
Análise de Sentimentos com TFX Pipelines — Local Deploy
Construa uma pipeline TFX local, crie um modelo de análise de sentimentos utilizando a arquitetura Transformer e disponibilize o modelo com TF Serving
1. Introdução
Nesse artigo, vamos abordar o processo de construção de uma pipeline para disponibilizar um modelo de análise de sentimentos com TFX Pipelines.
Este artigo é o primeiro de duas partes. Nessa parte, iremos abordar como rodar a nossa pipeline localmente. Na segunda parte, em CI/CD para TFX Pipelines com Vertex e AI Platform, abordaremos como disponibilizar nosso modelo na Google Cloud Platform (GCP) e como desenvolver nossa pipeline de CI/CD.
Ao fim desse artigo, você será capaz de:
- Criar um modelo de análise de sentimentos
- Criar uma pipeline integrando todos os componentes
- Servir seu modelo localmente através de uma API REST
- Analisar os metadados da sua pipeline
O código de toda a aplicação está disponível nesse repositório do GitHub.
2. TFX (TensorFlow Extended) + MLOps
Para construir nossa pipeline, vamos utilizar TFX.
De acordo com o TFX User Guide¹, “TFX é uma plataforma do Google-production-scale machine learning (ML) baseada no TensorFlow. Ele fornece uma estrutura de configuração e bibliotecas compartilhadas para integrar componentes comuns necessários para definir, iniciar e monitorar seu sistema de aprendizado de máquina.”
De acordo com Di Fante⁵, em MLOps existem três conceitos muito importantes:
- Data Provenance: de onde seus dados vem, como eles surgiram e quais metodologias e processos foram submetidos.
- Data Lineage: sequencia de passos até chegar no final da pipeline.
- Meta-data: dados que descrevem dados. Servem para explicar as caracteristicas do item que estamos observando.
Essas 3 peças são chave em modelos de produção, pois ajudam a rastrear as mudanças que ocorrem na vida útil do seu modelo. Modelos em produção possuem diversas versões, arquivos e pessoas envolvidos, por isso é importante trabalhar com frameworks que possuem mecanismos para reproduzir facilmente um ambiente ao qual nossa pipeline foi exposta, como TFX.
3. Pipeline
Um pipeline TFX é uma sequência de componentes que implementa um pipeline de ML especificamente projetado para tarefas de machine learning escalonáveis e de alto desempenho.
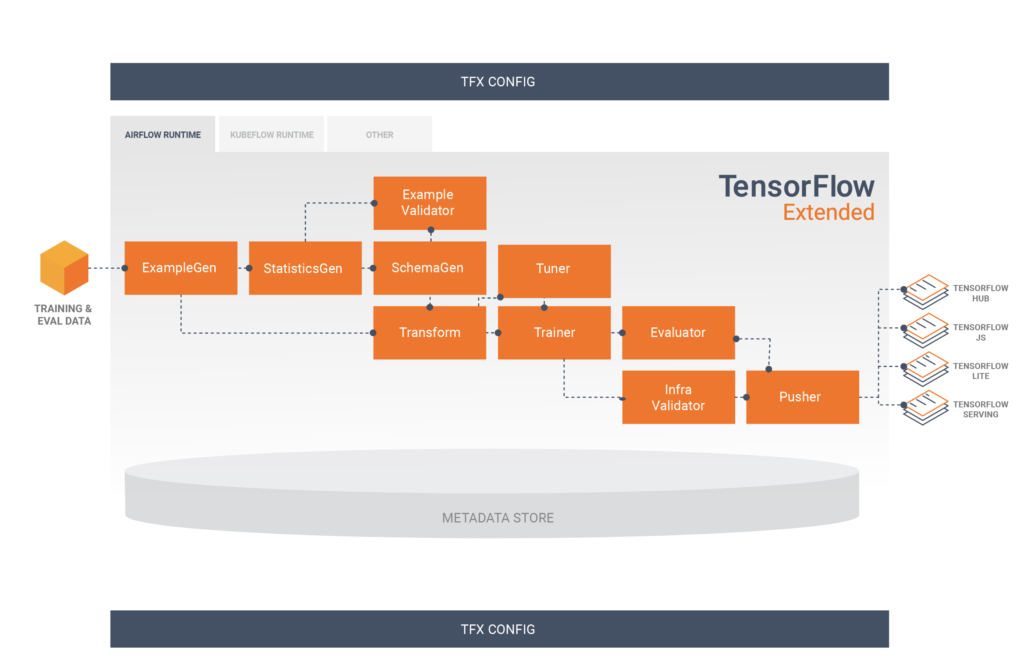
Cada componente é responsável por uma tarefa dentro da TFX Pipeline e, muitas vezes, um componente depende dos outputs do outro. TFX possui diversos tutoriais explicando como usar os componentes.
3.1 Componentes
No nosso caso, optamos por não utilizar o componente InfraValidator. Porém, optamos por adicionar um nó a mais na nossa pipeline, o Resolver. Resolver é um nó especial do TFX que lida com resolução de artefatos especiais, no nosso caso foi utilizado para especificar o último modelo base dentro do componente Evaluator.
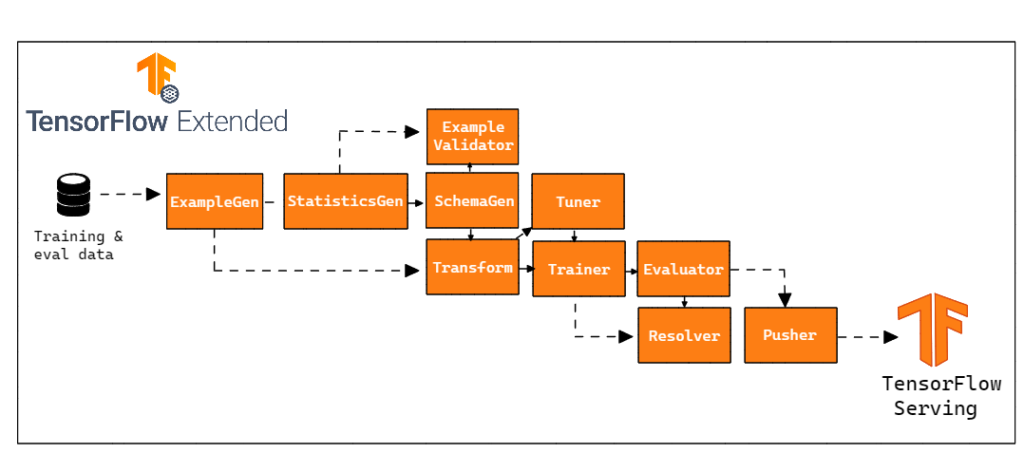
Dentro de run_pipeline.py, definimos a pipeline TFX. Todos os componentes e parâmetros estarão localizados nesse arquivo.
3.1.1 ExampleGen
É o componente de entrada inicial de um pipeline que processa e, opcionalmente, divide o conjunto de dados de entrada. Consome arquivos de fontes externas, como CSV, TFRecord, Avro, Parquet e BigQuery.
3.1.2 StatisticsGen
Calcula as estatísticas do conjunto de dados.
3.1.3 SchemaGen
Examina as estatísticas e cria um esquema de dados.
3.1.4 ExampleValidator
Procura anomalias e valores ausentes no treinamento e fornecimento dos dados, como detecção de desvios de dados.
3.1.5 Transform
Realiza a engenharia de atributos no conjunto de dados. Nesse componente realizamos todas as transformações/criações de variáveis do nosso modelo. Um ponto importante desse componente é que ele gera um grafo que guarda as propriedades globais dos dados, que será utilizado tanto no treinamento quanto na inferência, oferecendo confiabilidade.
3.1.6 Tuner
Ajusta os hiperparâmetros do modelo. O tuner pode ser executado em todas as execuções da pipeline, ou também pode ser importado, caso deseje realizar o ajuste de hiperparâmetros somente de tempos em tempos.
3.1.7 Trainer
Treina o modelo. É nesse componente que especificamos onde e como ele irá ser treinado, além de definir toda a arquitetura do mesmo.
3.1.8 Resolver
Um nó especial do TFX que lida com resolução de artefatos especiais, no nosso caso foi utilizado para especificar o último modelo base dentro do componente Evaluator.
3.1.9 Evaluator
Realiza uma análise profunda dos resultados do treinamento e ajuda a validar os modelos exportados, garantindo que eles sejam bons o suficiente para serem enviados para produção. Nesse componente é possível especificar thresholds de validação de métricas, evitando que o modelo vá para produção se não atingir os limites.
3.1.10 Pusher
Implanta o modelo em uma infraestrutura de exibição. É aqui onde especificamos onde o modelo irá ser servido.
Dessa maneira, a estrutura da nossa aplicação é essa:
│ run_local_pipe.ipynb
│
├───modules
│ │ label_encoder.pkl
│ │ model.py
│ │ preprocessing.py
│ │
│ ├───best_hyperparameters
│ │ best_hyperparameter.txt
│ │
│ └───data
│ data.csv
│
└───tfx-pipeline
│ kubeflow_v2_runner.py
│ local_runner.py
│
└───pipeline
│ configs.py
│ run_pipeline.py
No diretório tfx-pipeline temos os arquivos referentes às configurações dos orquestradores.
- local_runner.py — define parâmetros e variáveis para rodar a pipeline localmente
- kubeflow_v2_runner.py — define parâmetros e variáveis para rodar a pipeline localmente/cloud utilizando kubeflow como orquestrador
Em tfx-pipeline/pipeline temos arquivos referentes às configurações da pipeline
- configs.py — definir configurações globais da aplicação, como nome da pipeline e path de arquivos
- run_pipeline.py — definição da pipeline TFX, definição de todos os componentes e parâmetros
Em modules temos arquivos referentes à construção do modelo.
- label_encoder.pkl — objeto LabelEncoder do sci-kit learn para fazer o encode/decode da variável alvo
- model.py — construção do modelo de classificação (trainer component)
- preprocessing.py — transformação e pré-processamento de variáveis (transform component)
- best_hyperparameter.txt — arquivo derivado do Tuner Component, contendo os hiperparâmetros do modelo
Finalmente, com run_local_pipe.ipynb podemos criar e rodar nossa pipe localmente, além de analisar os artefatos gerados.
3.2 — Construção do Modelo
O nosso modelo é uma adaptação da arquitetura Transformer². O grande diferencial dessa arquitetura é a introdução do attention mechanism, que analisa a sequência de entrada e fornece um contexto sobre a importância de cada parte da sequência. Dessa maneira, diferente das Redes Neurais Recorrentes (RNN), essa arquitetura permite a paralelização de dados, diminuindo o tempo de treinamento.
O modelo foi construído com TensorFlow e o objetivo é classificar uma sentença em positiva, negativa ou neutra, então é um modelo de classificação.
Durante a construção da pipeline, existem dois componentes muito importantes: Transform e Trainer. Esses componentes, na nossa arquitetura, são representados pelos arquivos preprocessing.py e model.py, respectivamente. Vamos abordar cada um deles para entender o processamento das variáveis e a construção do nosso modelo.
3.2.1 Dados
Nossos dados de treinamento são títulos de reportagens em Português (PT-BR) e classificados entre: positive, negative ou neutral, já em formato numérico através de um LabelEncoder.

3.2.2 Preprocessing
Optamos por realizar poucas transformações nos dados de entrada. A função abaixo ilustra as transformações nos dados de entrada.
O foco principal é remover os acentos, caracteres especiais, números e stopwords das sequências de entrada.
3.2.3 Model
Não vamos entrar nos detalhes de todas as funções de carregamento/treinamento dos dados pois elas já estão extensivamente demonstradas nos tutoriais TFX.
Gostaria apenas de discutir 2 pontos importantes na definição do modelo: a arquitetura e as assinaturas.
Arquitetura
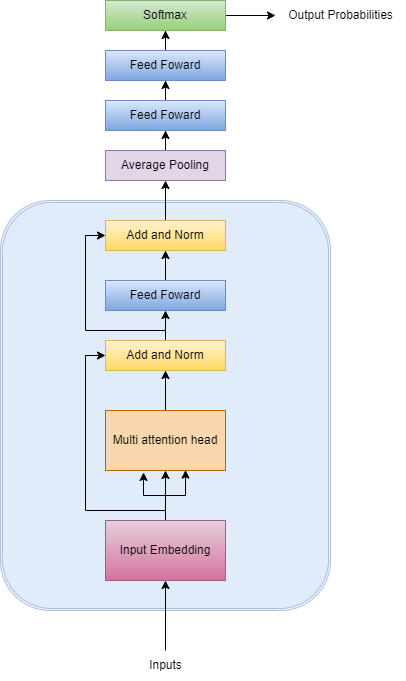
Como nosso modelo é uma adaptação da arquitetura original, optamos por torná-lo mais simples.
Nosso modelo recebe os inputs e transforma-os em embeddings, que são representações da sentença em forma de vetores. Após, os embeddings são passados para a camada multi-head attention, que irá criar vetores para cada palavra da sentença, representando a importância e a relação do contexto entre palavras. A camada de normalização é utilizada para ajudar a estabilizar o gradient descent e ajudar o modelo a convergir.
Finalmente, passamos os outputs para uma Feedfoward Network (FFN), uma camada simples que ajuda a transformar os vetores de atenção em uma forma digestível entre os blocos. Adicionamos mais algumas camadas semelhantes até definirmos a camada de saída, ativada pela função softmax, que possui como saída um vetor de probabilidades referente às 3 classes da variável alvo.
Dessa maneira, nosso modelo é construído da seguinte maneira:
Assinaturas
Ao disponibilizar modelos de machine learning, precisamos pensar em como nosso modelo irá receber os dados para previsão. Modelos TensorFlow possuem o formato SavedModel, que permitem que criemos diversas assinaturas para definir como nosso modelo irá receber os dados e disponibilizar as previsões.
Por isso, criamos uma assinatura que aceita inputs em forma de string ao invés do exemplo original do TFX, que espera os dados em formato tf.train.Example. A saída da nossa assinatura retorna as probabilidades de cada classe, a classe com maior probabilidade e o valor da maior probabilidade prevista.
Então, definimos as assinaturas do nosso modelo. No momento da predição, podemos escolher qual assinatura queremos e assim temos diversos formatos de dados aceitos pelo nosso modelo.
4. Local Deploy
Finalmente, podemos rodar a nossa pipeline. O notebook run_local_pipe.ipynb foi feito para criarmos, rodarmos e analisarmos nossa pipeline.
Utilizamos o TFX-cli para criar a pipeline, passando como argumento a engine local e o path para o arquivo desejado, neste, o local_runner.py.
E, finalmente, podemos executá-la.
Agora, todos nossos componentes serão executados e o nosso modelo está disponível para predições.
5. Servindo o modelo com TensorFlow Serving
Existem diversas maneiras de servir um modelo para predições, e uma delas é o TensorFlow Serving.
O TensorFlow Serving é um sistema de serviço flexível e de alto desempenho para modelos de aprendizado de máquina, projetado para ambientes de produção. O TensorFlow Serving facilita a implantação de novos algoritmos e experimentos, mantendo a mesma arquitetura de servidor e APIs. O TensorFlow Serving fornece integração pronta para uso com os modelos do TensorFlow, mas pode ser facilmente estendido para atender a outros tipos de modelos e dados.⁴
Primeiro, definimos onde nosso modelo está localizado e baixamos o pacote do TF-Serving.
E então, iniciamos o TensorFlow Serving. Aqui definimos alguns parâmetros importantes:
- rest_api_port: A porta que você vai usar para solicitações REST.
- model_name: Você vai usar isso na URL de pedidos REST. Pode ser qualquer coisa.
- model_base_path: Este é o caminho para o diretório onde você salvou o seu modelo.
5.1 Fazendo solicitações REST
Agora, estamos prontos para fazer solicitações. Carregamos o nosso encoder para transformar nossa variável alvo de acordo com o treinamento, definimos a url, nossa assinatura e dados que queremos prever. Após, fazemos uma solicitação de previsão POST para o nosso servidor, que retorna as probabilidades de cada exemplo participar das classes alvo, a classe prevista e o valor da maior probabilidade prevista.
6. Avalie os artefatos da pipeline
As saídas dos componentes de uma pipeline TFX são chamados de artefatos. Esses artefatos são registrados no repositório de metadados, que definimos nas configurações. Alguns desses artefatos podem ser visualizados de maneira gráfica, e fornecem informações valiosas sobre nossos dados.
Podemos acessar os artefatos produzidos pela nossa pipeline através do nosso repositório de metadados. Conseguimentos também filtrar tipos específicos de artefatos para visualizarmos e definir os paths da saída desses artefatos.
E, a partir desses artefatos, podemos visualizá-los graficamente. Vamos visualizar os resultados do StatisticsGen, por exemplo.
Podemos, então, visualizar lado a lado as estatísticas dos dados de treinamento e de validação.

7. Conclusão
Desenvolver uma pipeline local é o primeiro passo para integrarmos a nossa aplicação e conseguirmos padronizar o treinamento e a inferência do nosso modelo. Para evoluir nossa pipeline, na parte 2 desse artigo, vamos desenvolvê-la e fazer o deploy em um ambiente Cloud, além de aplicar práticas de CI/CD, tornando-a escalável e fácil de manter.
8. Referências
[1] The TFX User Guide (01 Setembro 2021), TensorFlow.
[2] Vaswani, A.; Shazeer, N., Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, L.; Polosukhin, I. Attention is all you need. (12 Junho 2017), arXiv preprint arXiv:1706.03762.
[3] Nandan, A. Text classification with Transformer (10 Maio 2020), Keras.
[4] TF Serving (28 Janeiro 2021), TensorFlow.
[5] Di Fante, A. L. How I deployed my first machine learning model (15 Dezembro 2021), arturlunardi.
[6] Amoateng, D. Text classification pipeline tfx local (01 Janeiro 2022), GitHub.