
CI/CD para TFX Pipelines com Vertex e AI Platform
Faça o deploy de uma TFX Pipeline com Vertex Pipelines, disponibilize seu modelo na AI Platform e construa uma pipeline de CI/CD para escalar seu sistema
1. Introdução
Este artigo é o segundo de duas partes, a primeira parte está disponível em Análise de Sentimentos com TFX Pipelines — Local Deploy. Na primeira parte foi abordado como desenvolver a pipeline localmente, além de mostrarmos o processo de construção de um modelo de análise de sentimentos.
Nessa parte iremos abordar como rodar a nossa pipeline em um ambiente Cloud, como desenvolver uma pipeline de CI/CD para TFX Pipelines e como monitorar as solicitações de request/response do nosso modelo.
Ao fim desse artigo, você será capaz de:
- Criar um modelo de análise de sentimentos
- Criar uma pipeline TFX integrada com Vertex AI
- Servir seu modelo em um ambiente cloud através de uma API REST
- Analisar os metadados da sua pipeline
- Criar uma pipeline de CI/CD
- Analisar inferências utilizando BigQuery
O código de toda a aplicação está disponível nesse repositório do GitHub.
2. Vertex AI + TFX Pipelines
Na primeira parte, explicamos o que é uma TFX Pipeline, o que são seus componentes e como nosso modelo funciona. Agora, vamos focar em como disponibilizar essa pipeline em um ambiente cloud e como construir uma pipeline de CI/CD para escalar nosso sistema.
Ao fazer o deploy de um modelo, precisamos pensar em como vamos disponibilizá-lo para o usuário final. Uma das maneiras mais utilizadas é através de solicitações em uma API REST.
Nesse tutorial vamos fazer o deploy da nossa pipeline utilizando os serviços da Google Cloud Platform (GCP), e de maneira geral, vamos utilizar dois serviços principais:
2.1 Vertex AI
Vertex AI é a nova plataforma de AI do Google e une todos os serviços do Google Cloud para criar ML. Vamos utilizar Vertex Pipelines para rodar nossas pipelines de treinamento, por dois principais motivos:
- Ela é mais barata — no nosso caso — do que a AI Platform Pipelines. Pipelines Vertex possuem taxas fixas de execução por run, associados também aos custos de treinamento do modelo através do Compute Engine. Não é necessário ativar e gerenciar clusters, tornando a infraestrutura mais enxuta e barata.
- Diferentemente do Google Kubernetes Engine (GKE) utilizado na AI Platform, não precisamos gerenciar a infraestrutura/saúde de servidores e clusters, já que a Vertex é uma plataforma autogerenciada.
2.2 AI Platform
Embora nossa pipeline seja executada utilizando Vertex Pipelines, nosso modelo será treinado e servido na AI Platform por um principal motivo:
Até essa data, não é possível informar a assinatura de um SavedModel TensorFlow através da função predict na Vertex AI.
Por isso, nossa pipeline foi construída para funcionar da seguinte maneira:
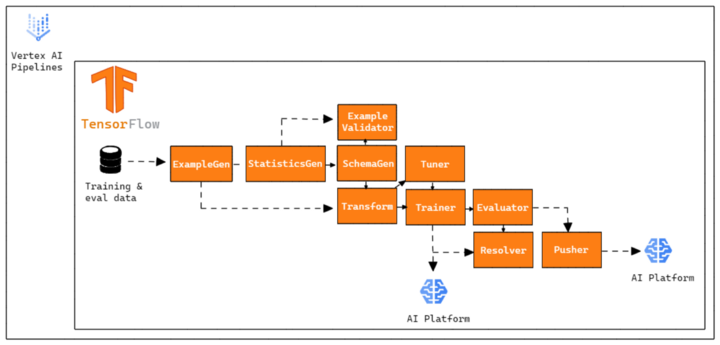
3. TFX Pipeline na Cloud
Agora, vamos entender como vamos migrar nossa pipeline para um ambiente Cloud.
3.1 Configurando o Projeto
Importante: esse projeto terá custos. Novos usuários do Google Cloud podem se qualificar para uma avaliação gratuita.
Primeiro de tudo, é necessário criar um projeto no Google Cloud Console e ativar as seguintes API’s:
- Vertex AI
- AI Platform Training & Prediction
- Cloud Storage
- Container Registry
- BigQuery
- Cloud Build
- Notebooks API
3.2 Configurações da Pipeline
Vamos agora abrir o arquivo configs.py e analisar algumas variáveis.:
- GCP_AI_PLATFORM_TRAINING_ARGS — Parâmetros passados para a AI Platform para treinar nosso modelo.
- GCP_AI_PLATFORM_SERVING_ARGS — Parâmetros passados para a AI Platform para servir nosso modelo.
Esses parâmetros são adicionados para criar a pipeline no arquivo kubeflow_v2_runner.py
Agora, vamos para as variáveis que apontam relativas à paths. Note, no código, que todas as variáveis apontam para Buckets no Google Cloud Storage, isso acontece porque como vamos montar nossa pipeline de CI/CD, esses arquivos estarão localizados e disponíveis no ambiente cloud.
- TRANSFORM_MODULE_FILE — Arquivo contendo as transformações do componente Transform.
- TRAIN_MODULE_FILE — Arquivo contendo as instruções do componente Trainer.
- TUNER_MODULE_PATH — Diretório contendo um arquivo best_hyperparameters.txt contendo os hiperparâmetros do modelo.
- DATA_PATH — Diretório contendo nossos dados.
- LABEL_ENCODER_FILE — Arquivo contendo nosso LabelEncoder para transformar nossas variáveis alvo.
3.3 Criando uma imagem Docker para o Cloud Build
Precisamos criar uma imagem Docker para ser utilizada pelo Cloud Build. Estamos criando essa imagem porque a versão Python fornecida pela imagem Python padrão é 3.9, porém a última versão TFX só suporta Python 3.8 ou menos.
Por isso, devemos acessar Vertex AI -> Workbench e criar um Notebook para definirmos nossa imagem. Esse passo também pode ser feito localmente ou no Cloud Shell.
Abra o terminal e clone o repo:
git clone https://github.com/arturlunardi/sentiment-analysis-tfx
Dentro do repositório, abra o notebook create_first_container.ipynb e execute as linhas para criar o container no caminho especificado.
Após a execução, você pode conferir a imagem no Container Registry.
3.4 Criando os buckets
Para que consigamos copiar os arquivos do nosso repositório para Buckets no Google Cloud Storage, precisamos criar as pastas para onde eles serão copiados.
Acesse o Google Cloud Storage no seu projeto e crie um Bucket com a seguinte estrutura de diretórios:
└───{{ GOOGLE_CLOUD_PROJECT }} + '-vertex-default'
└───{{ PIPELINE_NAME }}
├───best_hyperparameters
├───data
└───modules
3.5 Criando uma conta de serviço
Para que o GitHub Actions consiga executar as tarefas no Cloud Build, precisamos criar uma conta de serviço para autenticação.
Crie uma conta de serviço e adicione as seguintes permissões:
- Administrador AI Platform
- Agente de Serviço Vertex AI
- Agente de Serviço código personalizado Vertex AI
- Conta de Serviço do Cloud Build
- Leitor
Depois, crie uma chave em Chaves -> Adicionar Chave -> JSON.
Um último passo é necessário. Como vamos ler arquivos do Google Cloud Storage através do serviço da Vertex AI, precisamos dar permissão de leitura para a conta de serviço da Vertex AI.
Então, acesse IAM e administrador -> Marque Incluir concessões do papel fornecidas pelo Google, à direita -> Localize a conta com nome: AI Platform Custom Code Service Agent -> Adicione o papel de Leitor.
3.6 Definindo Secrets no Git Repo
Nossa Pipeline de CI/CD irá utilizar algumas variáveis que são secretas, por isso, precisamos adicioná-las.
Acesse o seu repositório -> Settings -> Secrets -> Actions e crie os seguintes secrets:
- GCP_PROJECT_ID: o id do seu projeto
- GCP_CREDENTIALS: copie e cole todo o conteúdo da chave JSON da conta de serviço criada acima
4. Pipeline de CI/CD
De acordo com Park, C.; Paul, S.², na engenharia de software, Integração Contínua (CI) e Entrega Contínua (CD) são dois conceitos muito importantes. CI é quando você integra mudanças (novos recursos, confirmações de código aprovadas, etc.) em seu sistema de forma confiável e contínua. CD é quando você implanta essas alterações de forma confiável e contínua. CI e CD podem ser realizados isoladamente, assim como podem ser acoplados.
Para tornar o nosso sistema escalável, precisamos trabalhar com práticas CI/CD. Isso irá nos permitir aplicar experimentos, integrações e deploys de maneira muito mais rápida e confiável. Vamos analisar alguns cenários:
- Com novos dados disponíveis, como retreino meu modelo regularmente?
- Ao adicionar novas features, como tenho certeza que meu sistema não vai quebrar?
- Após implantar meu modelo, como testo o serviço de previsão através da API para garantir que as entradas e as previsões estão sendo interpretadas corretamente?
Implementar ML em produção não significa apenas disponibilizar o modelo através de uma API, mas sim implementar uma pipeline escalável e adaptável a mudanças, que permita uma experimentação rápida e forneça resultados precisos. Caso deseje saber mais sobre pipelines CI/CD e da importância delas, recomendo esse artigo do Google, MLOps: Continuous delivery and automation pipelines in machine learning.
Nesse projeto, nossa pipeline CI/CD vai funcionar da seguinte maneira:
- Criamos um repositório no Github, contendo todo o código da nossa TFX Pipeline que será executada no Vertex AI.
- Configuramos um fluxo no GitHub Actions, que irá disparar a cada push no master branch, e checará se houveram mudanças em diretórios específicos do nosso repositório.
- Se houverem mudanças, execute uma ação específica para cada tipo de alteração.
O seguinte arquivo YAML define uma GitHub Actions ativada por um push no master branch.
Vamos entender um ponto importante: o dorny/paths-filter do GitHub Actions nos permite detectar se houveram alterações em determinados paths feitos com o push.
Nesse caso, estamos analisando dois caminhos: tfx-pipeline e modules:
- Se houveram mudanças no path tfx-pipeline, inicie um Cloud Build Process com as configurações dispostas no arquivo build/full-pipeline-deployment.yaml, utilizando as variáveis de ambiente através de— substitutions.
- Se houveram mudanças no path modules e não houveram mudanças em tfx_pipeline (para não haver runs duplicadas), inicie um Cloud Build Process com as configurações dispostas no arquivo build/partial-pipeline-deployment.yaml, utilizando as variáveis de ambiente através de— substitutions.
Vamos analisar agora com cuidado os dois arquivos.
4.1 full-pipeline-deployment.yaml
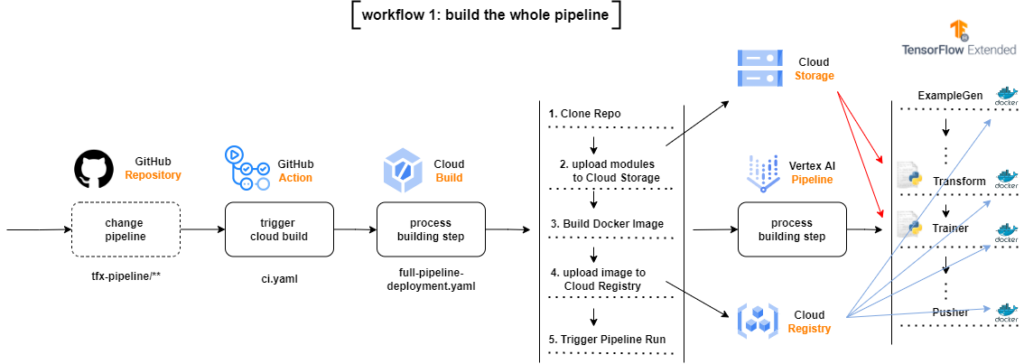
Caso hajam mudanças no diretório que contenham arquivos relativos às configurações da pipeline, o fluxo irá iniciar um Cloud Build Process, que irá clonar o repositório inteiro, copiar apenas os módulos alterados para os diretórios dos módulos no Google Cloud Storage Bucket, construir uma nova imagem Docker baseada nas mudanças do código, subir a nova imagem para um Google Container Registry e submeter a TFX Pipeline no Vertex AI.
Pode ser difícil de ler da primeira vez, mas se analisarmos passo por passo entendemos o que está acontecendo:
- Clonamos o repositório inteiro
- Copiamos alguns arquivos desse repositório para os Buckets especificados
- Compilamos a pipeline para checar se está tudo certo
- Criamos a pipeline com tfx pipeline create
- Criamos a run no Vertex AI com tfx run create
Existem três pontos importantes nesse arquivo:
- a flag — build-image em tfx pipeline create serve para criarmos uma nova imagem Docker do nosso ambiente
- a imagem Docker utilizada pelo cloud build é gcr.io/$_PROJECT/cb-tfx:latest, ou seja, a imagem que criamos no passo 3.3
- definimos a engine do tfx run create como vertex, pois estamos submetendo a nossa pipeline na Vertex AI.
4.2 partial-pipeline-deployment.yaml
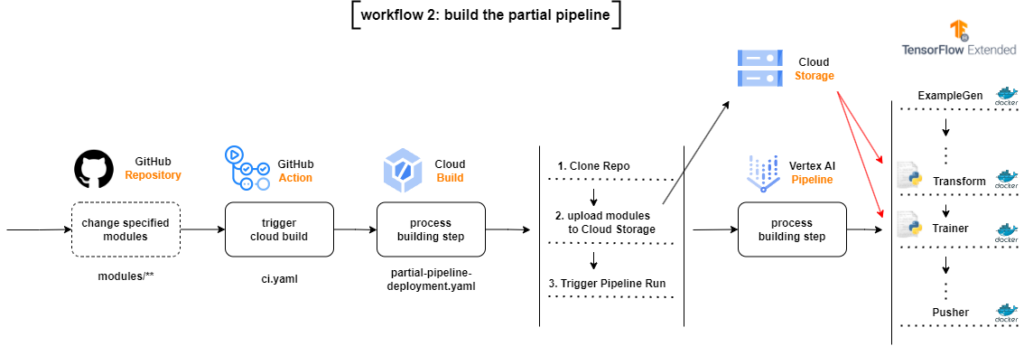
Caso hajam mudanças no diretório que contenham mudanças no código do modelo, do pré-processamento, dos dados de treinamento, hiperparâmetros ou LabelEncoder:
- O fluxo irá iniciar um Cloud Build Process, que irá clonar o repositório inteiro
- Copiar apenas os módulos alterados para os diretórios dos módulos no Google Cloud Storage Bucket
- Submeter a TFX Pipeline no Vertex AI, sem a necessidade de construir uma nova imagem Docker
Esse arquivo é praticamente igual ao full-pipeline-deployment.yaml, as diferença são:
- a flag— build-image em tfx pipeline create foi removida, já que não precisamos criar uma nova imagem Docker
- já que não houveram alterações nas configurações da pipeline, não precisamos compilá-la, removendo o tfx pipeline compile.
5. Monitoramento
Ao implantar um modelo em produção, precisamos monitorá-lo constantemente. Nosso modelo foi treinado em um determinado conjunto de dados, por isso, para manter o desempenho, os dados aos quais ele será exposto precisam possuir a mesma distribuição.
Como os modelos não operam em um ambiente estático, o desempenho deles podem degradar-se ao longo do tempo devido à desvios entre os dados de treinamento e os dados de previsão. Alguns exemplos de desvios podem ser:
- Introdução de um novo vocabulário (uma nova língua)
- Alteração nas unidades de medida (metros para km)
- Alteração no comportamento do consumidor devido a algum evento externo (pandemia)
Como o modelo não foi exposto a essas mudanças, a tendência é que o desempenho seja afetado. Por isso precisamos monitorar:
- Como os dados mudam com o tempo
- Quando é necessário retreinar o modelo para capturar os novos padrões
- Se os dados que estão sendo ingeridos são os mesmos aos quais meu modelo foi exposto
Nesse exemplo, vamos registrar todos os registros de request/response do nosso modelo. O nosso modelo estará disponbilizado na AI Platform, e os registros serão salvos em uma tabela do BigQuery em formato bruto (JSON)
A arquitetura que vamos criar é mostrada no diagrama a seguir:
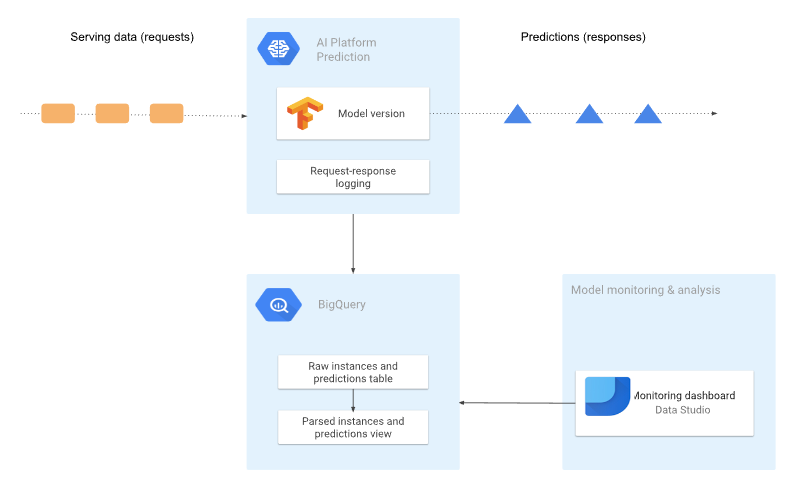
5.1 Ativando o registro de solicitações de request/response no BigQuery
Por padrão, o AI Plaform Prediction não registra as solicitações, pois esses registros geram custos. Modelos podem receber um número muito alto de solicitações, acarretando em um custo considerável, dessa maneira precisamos ativar explicitamente os registros. O código está disponível no arquivo activate_logging_requests.ipynb.
Antes de ativar os registros, precisamos criar uma tabela no BigQuery para guardar os registros.
Toda tabela precisa estar dentro de um BigQuery Dataset, por isso definimos o nome do dataset e da tabela e criamos o dataset.
Após, definimos o esquema de dados esperado pela tabela.
Criamos a tabela. Note que não definimos nenhum tempo de expiração para a tabela, se deseja saber mais sobre, acesse a documentação.
Agora podemos ativar a geração de registros do nosso modelo. Um ponto importante é que precisamos definir a versão do modelo que desejamos ativar os registros. Para cada versão do modelo, precisamos explicitamente ativar os registros.
Buscamos dentro do nosso modelo qual a última versão.
E, finalmente, ativamos a geração de registros. O argumento samplingPercentage define a porcentagem de solicitações que desejamos registrar, no nosso caso definimos 1.0, ou seja, registramos 100% dos registros.
Na nossa tabela estarão todos os registros, de forma bruta, de todas as versões do nosso modelo.
5.2 Visualizando nossos dados
Conforme vemos abaixo, nossos dados são registrados de maneira bruta, no formato JSON.
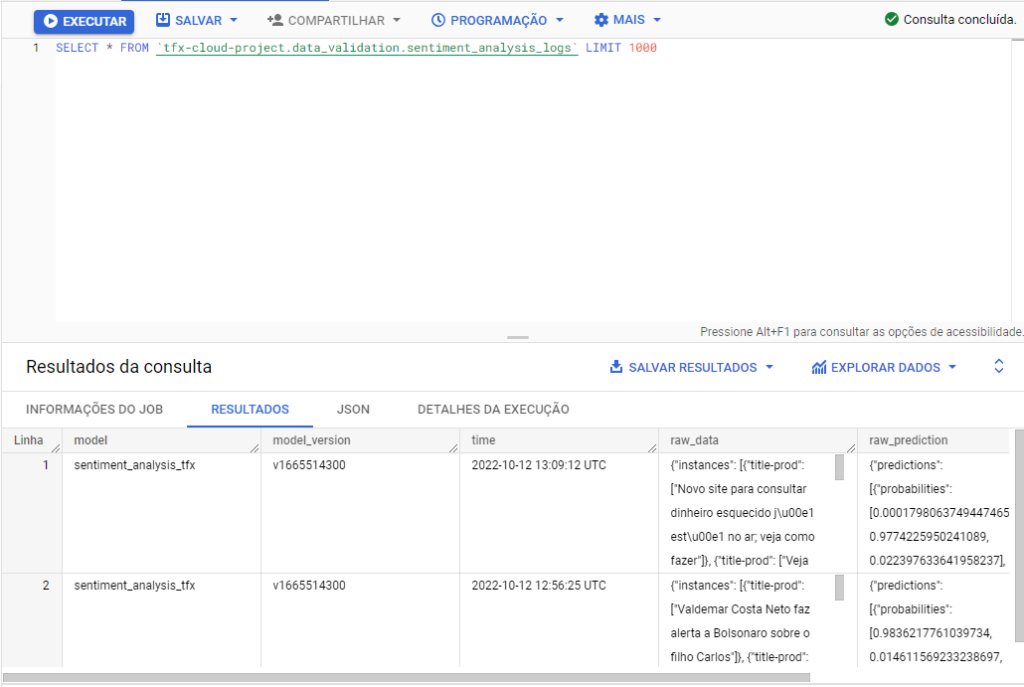
Para melhorar nossa visualização, podemos criar uma view específica dos nossos dados. Vamos entender o esquema da tabela do BigQuery.
https://gist.github.com/arturlunardi/567340f91a68d6d6b30d649aed28b126#file-schema_bigquery_table-csvNa tabela a seguir, mostramos um exemplo dos dados armazenados nas colunas raw_data e raw_prediction da tabela do BigQuery, respectivamente.
Agora, no arquivo create_view.py definimos a criação da view. Primeiro, criamos algumas funções auxiliares.
Após, definimos a função que irá criar a view, recebendo todos os parâmetros. Vamos separar em quatro partes:
- Definimos as features e a variável alvo.
2. Definimos duas variáveis json_features_extraction e json_prediction_extraction. Essas variáveis contêm os atributos e os valores de previsão em um formato que pode ser inserido em uma instrução SQL.
3. Criamos a variável sql_script, que contém a instrução CREATE OR REPLACE VIEW. A instrução contém vários marcadores, que são marcados na string usando @ como prefixo.
4. Finalmente, substituimos os marcadores na instrução SQL pelas variáveis definidas anteriormente e criamos a view.
Agora, podemos acessar o console do BigQuery e acessar nossos dados.
E a saída é semelhante a essa.
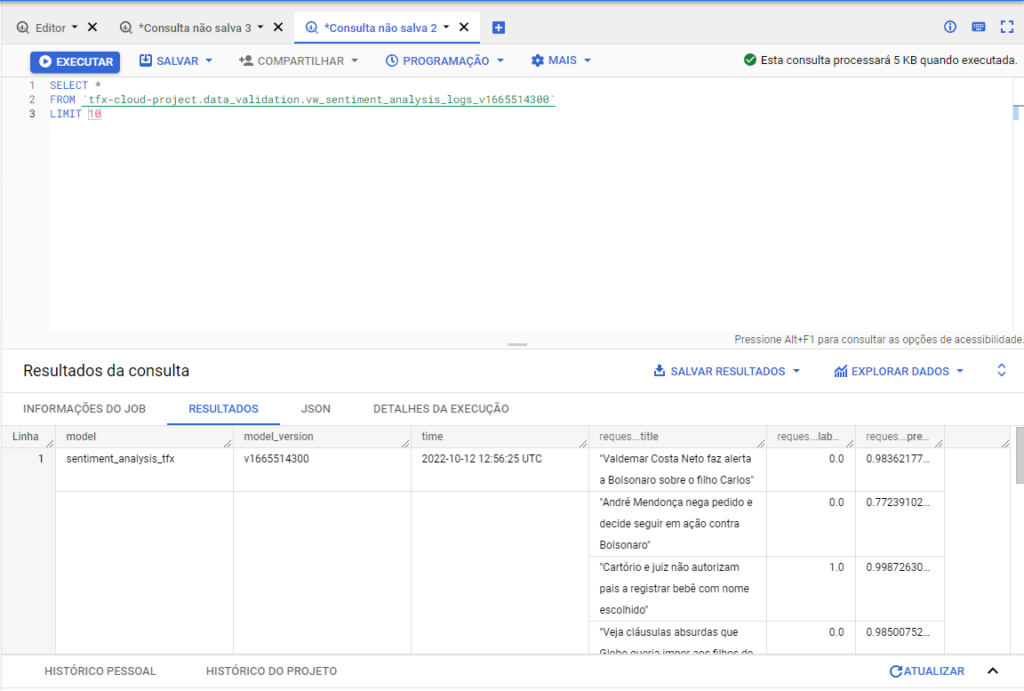
Podemos, também, utilizar o Google Loker para criar dashboards e visualizações interativas dos nossos dados.
Para limpar todos os recursos do Google Cloud usados neste projeto, você pode excluir o projeto do Google Cloud usado no tutorial.
6. Conclusão
Desenvolver pipelines em um ambiente cloud permite que o nosso sistema se torne escalável e menos suscetível a erros. Fazer o deploy do modelo é apenas uma parte de todo o processo, para mantermos o desempenho das nossas previsões precisamos monitorar constatemente as inferências e analisar quais dados estão sendo enviados ao nosso modelo.
Pipelines de CI/CD fornecem responsividade ao nosso sistema, permitindo ciclos de teste mais rápidos, maior confiabilidade no deploy dos modelos, melhora na qualidade do código e loops de feedback mais curtos.
7. Referências
[1] MLOps: Continuous delivery and automation pipelines in machine learning (07 Janeiro 2020), Google.
[2] Park, C.; Paul, S. Model training as a CI/CD system: Part I (6 Outubro 2021), Google.
[3] ML model monitoring: Logging serving requests by using AI Platform Prediction (12 Março 2021), Google.
[4] Analyzing AI Platform Prediction logs in BigQuery (12 Março 2021), Google.
[5] Di Fante, A. L. How I deployed my first machine learning model (15 Dezembro 2021), arturlunardi.
[6] TFX on Cloud AI Platform Pipelines (05 Novembro 2021), TensorFlow.
[7] Simple TFX Pipeline for Vertex Pipelines (08 Dezembro 2021), TensorFlow.