Como criar um Web App de ML com Streamlit e Pipelines
Envolva seus processos em uma pipeline do scikit-learn, aprenda a criar um web app de ML com streamlit e forneça uma interface amigável
1. Introdução
As empresas têm grande interesse em comunicar suas soluções aos clientes. É do interesse das pessoas saber como o modelo funciona e como se comporta quando é apresentado a novos dados. Quando você constrói seu modelo e o fornece iterativamente, ele aproxima sua empresa dos clientes. Por isso, nesse artigo, vamos criar um Web App de ML com Streamlit e Pipelines do scikit-learn para fornecer uma interface amigável ao usuário.
Dashboards e/ou Web Apps são maneiras comuns de apresentá-lo e há várias opções de ferramentas, como Tableau, PowerBI, Flask, Django etc. No entanto, esses tipos de aplicativos costumam consumir muito tempo e envolvem custos mais elevados .
Uma boa alternativa para as abordagens mais tradicionais, então, é usar o Streamlit.
Streamlit é uma biblioteca Python de código aberto que facilita a criação e o compartilhamento de belos aplicativos da web personalizados para aprendizado de máquina e ciência de dados.
Nosso Web App será capaz de:
- Realizar a análise exploratória dos dados (EDA)
- Prever preços de aluguel através de inputs do usuário em 20 modelos de machine learning
- Realizar a avaliação de cada um dos modelos
O código da aplicação e a construção dos modelos estão disponíveis nesse repositório do Github. O app também está disponível no Streamlit Share, disponível publicamente neste link.
2. Visão Geral do Modelo
Neste tópico, discutiremos as decisões relativas à construção dos modelos de machine learning.
2.1 Dataset
Trabalharemos com um conjunto de dados do Kaggle, fornecido a partir desta fonte. É um arquivo csv com 10.962 registros e 13 recursos. Nossa variável alvo é o valor do aluguel (R$), portanto é um problema de regressão.

2.2 Estrutura
Nosso objetivo ao criar o Web App com Streamlit é reduzir a complexidade e fornecer um aplicativo amigável. Portanto, precisamos realizar todas as etapas de construção do modelo antes de implementá-lo e armazená-lo de maneira fácil.
Existem 6 etapas para definir o modelo:
- EDA
- ETL
- Data Cleansing
- Feature Engineering
- Definição do Modelo
- Avaliação do Modelo
Todas as etapas foram realizadas em Jupyter Notebooks. Para o ETL e as etapas de limpeza de dados, novos arquivos csv foram gerados para diferenciar do original.
2.3 Definição do Modelo
Uma boa prática no desenvolvimento de modelos de aprendizado de máquina é usar pipelines. Optamos por usar a classe Pipeline do scikit-learn, que de acordo com a documentação:
O objetivo da pipeline é reunir várias etapas que podem ser validadas em conjunto durante a definição de parâmetros diferentes.
As pipelines fornecem uma sequência lógica de etapas que podem fornecer uma transformação consistente que nos garantirá que todos os dados seguirão as mesmas etapas.
“Coletivamente, a sequência linear de etapas necessárias para preparar os dados, ajustar o modelo e transformar as previsões é chamada de pipeline de modelagem.” — Jason Brownlee
2.3.1 Passos da Pipeline
Quando estamos construindo nosso modelo, temos que definir as transformações que vamos realizar nos dados e as combinações que queremos comparar. Existem transformações que são feitas em cada combinação e outras através das quais iteramos.
Neste exemplo, optamos por comparar os resultados de acordo com a criação de novos recursos e transformações da variável alvo. Portanto, existem 4 combinações.
Vamos enumerar as etapas do pipeline. Aqueles com * fazem parte da combinação. A etapa de seleção de K atributos é exclusiva para trabalhar com redes neurais, que iremos abordar adiante.
- Feature Engineering*
2. Pré-processamento
3. Seleção de K atributos
4. Modelo
5. Transformação da Variável Alvo*
Agora, vamos passar por todas as etapas.
2.3.1.1 Feature Engineering
Feature Engineering é uma parte importante do processo e pode ajudar o modelo a entender melhor as relações subjacentes dos dados.
Em nosso exemplo, criaremos uma classe chamada FeatureCreation, ela será passada como uma etapa para o pipeline e criará atributos dentro da pipeline, deixando nosso conjunto de dados original intacto. Vamos usar as classes BaseEstimator e TransformerMixin do scikit-learn, nossa classe herdará dessas classes pois elas nos fornecem métodos pré-existentes gratuitamente.
2.3.1.2 Pré-processamento
O pré-processamento é importante para tornar os dados adequados para os modelos. Optamos por aplicar One Hot Encoding nas variáveis categóricas e padronizar as variáveis numéricas. Usamos a classe ColumnTransformer, que envolve as etapas.
2.3.1.3 Seleção de K Atributos
Esta etapa é exclusiva para Redes Neurais. Para criar uma rede neural, temos que especificar a dimensão de entrada dela e, como estamos criando atributos e realizando transformações, como o one hot encoding, não podemos garantir o número exato de atributos que existirão.
Uma maneira de contornar isso é definir um valor fixo de variáveis que serão passadas, e isso é possível usando SelecKBest do scikit-learn. Esta função pontua as variáveis de acordo com a função passada, no nosso caso, f_regression, e retorna as k variáveis definidas. Com o número de recursos, apenas passamos a dimensão de entrada para a rede neural e criamos outra etapa em nosso Pipeline.
2.3.1.4 Modelo
Esta etapa é muito simples, fornecemos apenas um modelo para o pipeline. Neste exemplo, optamos por trabalhar com 5 modelos para ver o desempenho de cada um, são eles:
- RandomForest
- XGBoost
- LGBM
- Ridge
- Rede Neural
Estes modelos foram escolhidos por possuírem diferentes mecanismos de trabalho, RandomForest realiza bagging, XGBoost e LGBM realizam boosting, Ridge é um modelo linear e a Rede Neural possui arquitetura própria.
Como temos 4 combinações e 5 modelos, acabaríamos com 20 modelos treinados.
2.3.1.5 Construa a Pipeline
Agora, apenas instancie a Pipeline e crie as etapas. As etapas seguem uma sequência lógica e serão realizadas uma após a outra.
2.3.1.6 Transformação da Variável Alvo
Quando estamos realizando o EDA, exploramos a distribuição da variável de destino. Frequentemente, a distribuição não segue uma distribuição gaussiana, ou normal, portanto, podemos precisar realizar transformações para torná-la o mais normal possível para que o modelo tenha um bom desempenho.
Em nosso caso, optamos por realizar a transformação logarítmica antes de ajustar o modelo, isso reduzirá ou removerá a assimetria da variável. O transformador realizará uma transformação de log antes do ajuste e, ao prever os valores, realizará uma transformação exponencial, trazendo o valor de volta à escala original.
Para fazer isso, usaremos a classe TransformedTargetRegressor do scikit-learn. Este objeto recebe um regressor, que é nossa pipeline com nosso modelo e etapas, uma função e uma função inversa.
Isso fecha nosso processo em relação às etapas do pipeline.
2.3.2 Otimização de Hiperparâmetros e Validação Cruzada
Para obter resultados melhores e mais consistentes, podemos realizar um ajuste de hiperparâmetros e validação cruzada em nossos modelos.
Existem várias maneiras de realizar um ajuste de hiperparâmetros, as mais conhecidas são a grid search e a random search.
Neste exemplo, optamos por usar a random searchem vez da grid search porque as pesquisas mostram que a random search faz um trabalho melhor com menos recursos. Cada modelo terá sua própria grade, que são os parâmetros que queremos otimizar e a gama de valores disponíveis.
Agora, iteramos por meio de cada modelo e armazenamos os resultados. O RandomizedSearchCV retorna o modelo com os melhores parâmetros, então podemos armazená-lo.
Para validação, usaremos a validação cruzada K-Fold. Isso significa que os dados serão divididos por K grupos de amostras, chamados folds. Então, a cada iteração de K, os dados serão treinados em K-1 e testados nas demais. Nossa métrica para avaliação é RMSE.
Agora, basta iterar em cada modelo novamente, realizar a validação cruzada e armazenar as métricas. Não se esqueça de fazer o fit do modelo se quiser salvá-lo.
2.3.3 Salvando os Modelos
Nos tópicos acima, executamos as etapas de definição do modelo, mas para trabalhar com isso em uma aplicação web, precisamos salvar nossos modelos e carregá-los posteriormente. Existem vários métodos para serializar um modelo e salvá-lo, neste exemplo optamos por trabalhar com Pickle.
Como estamos trabalhando com objetos Pipelines e TransformedTargetRegressor e também com modelos Keras em redes neurais, temos algumas particularidades.
Os modelos Keras não são serializados por pickle, então precisamos salvá-lo diretamente em um arquivo diferente e redefinir o parâmetro dentro dos pipelines para evitar a geração de um erro.
Quando estamos trabalhando com pipelines, devemos acessar a etapa onde o modelo está armazenado para salvá-lo. Com TransformedTargetRegressor é semelhante, mas precisamos dar mais um passo e acessar o parâmetro do regressor antes de acessar a etapa do modelo.
Mais tarde, temos que reconstruir o pipeline de carregamento dos modelos Keras e colocá-lo de volta nas etapas.
Posteriormente, na avaliação do modelo, temos que identificar qual arquivo corresponde a cada modelo. Para fazer isso, criamos um dataframe com cada modelo, suas métricas e nome de arquivo, para que possamos identificá-los mais tarde.
Agora, temos todos os modelos treinados e armazenados em um arquivo. Para realizar uma previsão, basta carregar o arquivo e usar o método de previsão que nosso pipeline fará o resto.
3. Web App com Streamlit
É hora de liberar a criatividade, vamos criar nosso Web App de ML com Streamlit! O Streamlit é executado em um script python e permite que você crie rapidamente uma interface amigável. Não cobriremos todos os aspectos do script, apenas uma visão geral de como ele foi estruturado e funciona.
3.1 Fluxo de Dados
O Streamlit possui uma maneira única de lidar com o fluxo de dados. Como você não precisa fazer nenhum callback para seu aplicativo, toda vez que algo muda em seu código, como uma variável ou os argumentos de uma função, streamlit executará novamente seu script.
Essa facilidade tem um custo, se seu aplicativo tiver operações computacionalmente custosas, como carregar dados de um banco de dados ou um grande gráfico, pode comprometer seu desempenho. E é por isso que streamlit tem um método st.cache que pode armazenar em cache uma função e armazenar as informações sobre ela, se os argumentos dessa função não mudarem, streamlit não irá executá-la novamente, melhorando o desempenho.
3.2 Estrutura
O Streamlit permite que você crie aplicativos de várias páginas facilmente, interagindo com os widgets na barra lateral.
Em nosso aplicativo, teremos 4 páginas.
- Introdução
- EDA
- Previsão do Modelo
- Avaliação do Modelo
Em todas as condições, podemos criar uma página única, e para navegar pelas páginas, basta selecionar a opção no widget.
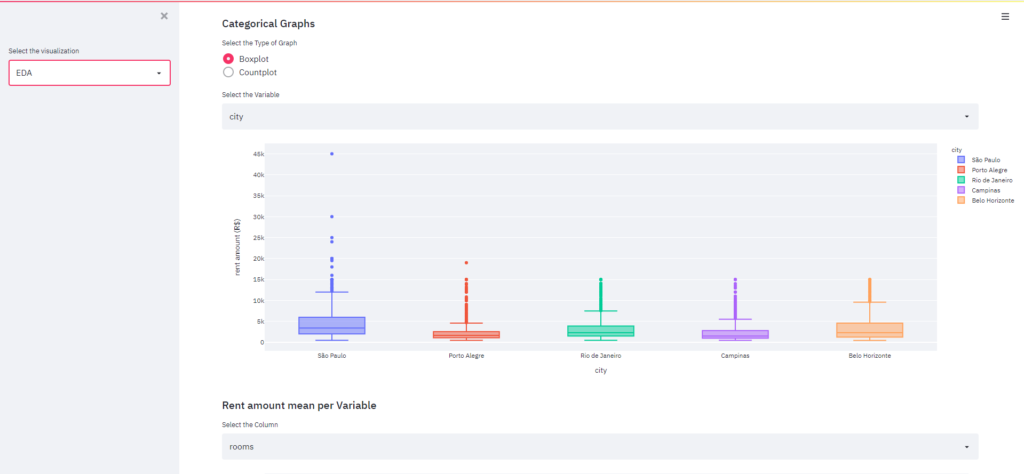
3.3 EDA
No EDA, criamos um widget que o usuário pode selecionar o tipo de dado, bruto ou o limpo. Os gráficos serão gerados com base neste conjunto de dados.
Streamlit oferece suporte a várias bibliotecas de gráficos diferentes, optamos por trabalhar com Plotly. Criamos funções personalizadas para cada gráfico para personalizá-los e armazená-los em cache.
Agora, basta importar o módulo e usá-lo dentro do script do aplicativo. Streamlit tem métodos específicos para as bibliotecas, mas você também pode usar st.write. Você pode brincar com os widgets e alterar o gráfico à medida que o usuário interage.
Agora, só temos que preencher nosso EDA com os gráficos que desejamos.
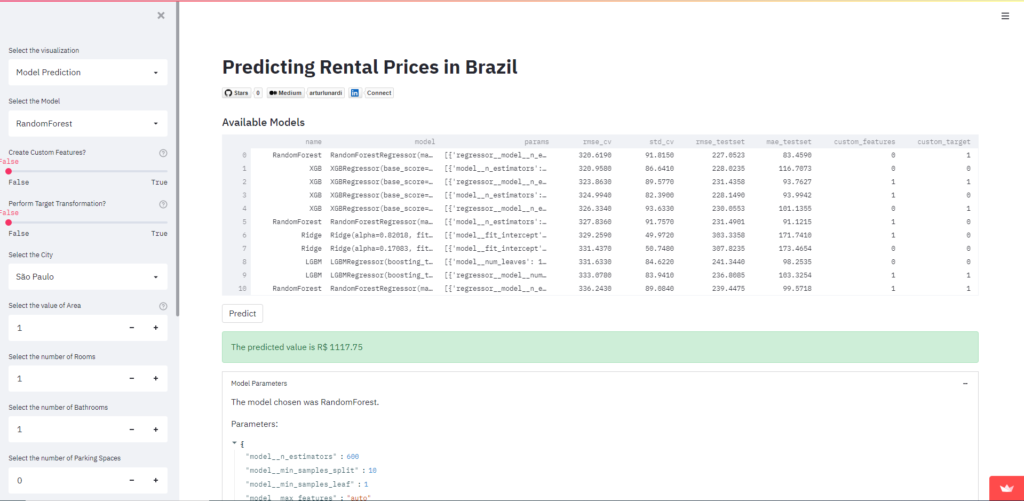
3.4 Previsão do Modelo
Para realizar previsões com os modelos, devemos carregá-los. Na definição do modelo, criamos os arquivos e o dataframe com cada nome de arquivo para cada modelo, vamos carregá-los.
Observe que armazenamos em cache o dataframe que contém os modelos, o que melhora o desempenho de nossas previsões, já que não precisamos carregá-lo todas as vezes. Também reconstruímos os modelos Keras dentro dos objetos Pipeline e TransformedTargetRegressor.
Agora é hora de permitir que o usuário decida qual modelo deseja usar.
Crie widgets para cada dado que será previsto.
E, finalmente, preveja o valor com o modelo escolhido e exiba-o junto com os parâmetros do modelo!
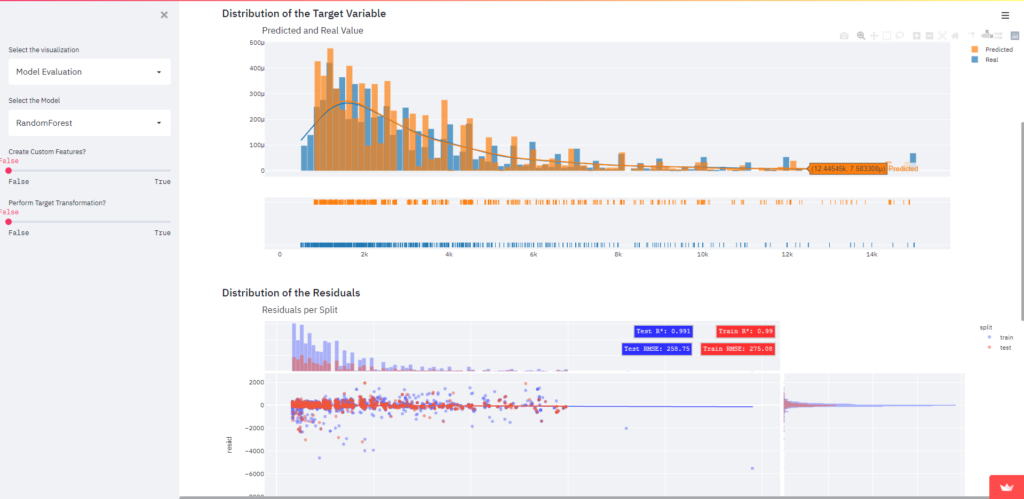
3.5 Avaliação dos Modelos
Em nosso Jupyter Notebook de avaliação dos modelos, dividimos nosso conjunto de dados em treino e teste e definimos um estado aleatório. Agora, na avaliação do modelo, vamos analisar as previsões dos modelos com base em dados que o modelo nunca viu.
Primeiro, apenas selecionamos o modelo que desejamos analisar, semelhante à página de previsões do modelo. Em seguida, geramos os gráficos.
Escolhemos exibir:
- Distribuição das variáveis previstas em comparação com os valores reais
- Resíduos das previsões nos dados de treino e teste
- Boxplot dos RMSE gerados pelos 5 folds da Validação Cruzada
Você pode gerar gráficos e relatórios para analisar cada modelo separadamente!
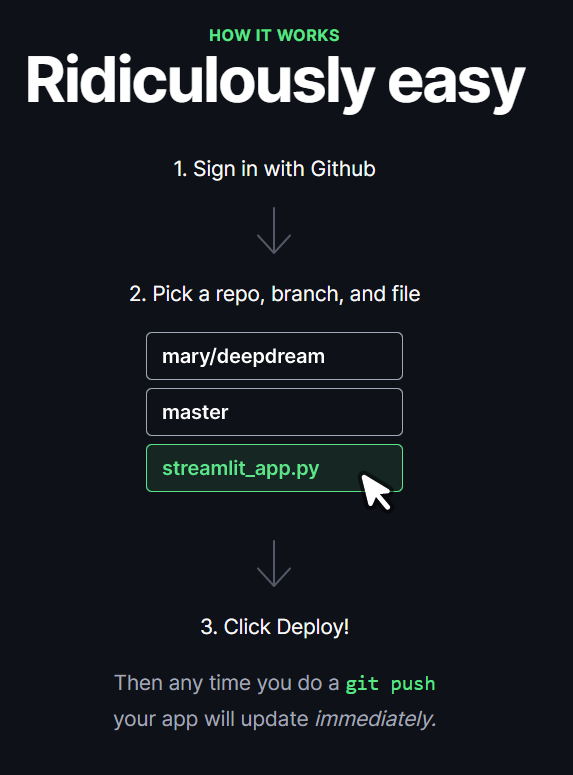
3.6 Deploy do Modelo
Agora que o aplicativo está construído, só temos que implantá-lo e fazemos isso muito facilmente com o Streamlit Share.
Você só precisa solicitar acesso, selecionar seu repositório github, branch e arquivo e clicar em implantar. Depois disso, seu aplicativo está disponível publicamente e hospedado!
4. Conclusão
Comunicação é uma habilidade crucial de um cientista de dados, muitas vezes os resultados são complexos e difíceis de explicar e apresentá-los a um público não técnico é um desafio. Para ilustrar a importância deste tópico, Hadley Wickham diz em seu livro R for Data Science:
Não importa o quão boa seja sua análise, a menos que você possa explicá-la a outros: você precisa comunicar seus resultados.
Quando você entrega um projeto, os clientes ficam curiosos não só para ver os resultados, mas para saber como funciona. Por isso, podemos envolver todos nossos processos dentro de uma Pipeline do scikit-learn e criar Web App de ML com Streamlit para disponibilizar os resultados com uma interface amigável.
5. Referências
[1] W. Hadley; G. Garret, R for Data Science: Import, Tidy, Transform, Visualize, and Model Data (2017), 1st Edition, O’Reilly.
[2] A. Muhammad, Streamlit Tutorial: Deploying an AutoML Model Using Streamlit (2021), Omdena.
[3] P. Sadrach, A Beginner’s Guide to Building Machine Learning-Based Web Applications With Streamlit (2021), Builtin.
[4] B. Jason, A Gentle Introduction to Machine Learning Modeling Pipelines (2021), Machine Learning Mastery.