
Como eu fiz o deploy do meu primeiro modelo de machine learning
Processos e ferramentas que utilizei para disponibilizar o meu primeiro modelo de machine learning
1. Introdução
Uma das palavras que mais ouvimos em machine learning é o termo deploy. O deploy de um modelo de machine learning nada mais é que um processo onde disponibilizamos um modelo de machine learning para outras pessoas, e é justamente nessa etapa que vemos como o modelo se torna um produto.
Ao disponibilizar um modelo para usuários, surgem diversas perguntas, como:
- Como o modelo é produzido e testado?
- Como o modelo é monitorado?
- Como eu atualizo meu modelo?
- Quais frameworks e ferramentas utilizo?
Nesse artigo, explico um pouco sobre como foi o processo de produção para fazer o deploy do meu primeiro modelo de machine learning com viés comercial, desde a produção da Pipeline, monitoramento do modelo, disponibilização para o usuário final e integração/entrega contínua (CI/CD). O objetivo é ser direto e focar no processo de produção, explicando quais decisões foram tomadas e o porquê delas, explicando também quais ferramentas foram utilizadas para auxiliar no processo de construção e deploy do modelo. Nesse artigo não temos nenhum tipo de código, apenas explicações de como foi o processo de produção.
2. TFX (TensorFlow Extended)
O modelo foi construído com TFX e grande parte do conteúdo aplicado foi aprendido através do Programa de Cursos Integrados Machine Learning Engineering for Production (MLOps), ministrado por profissionais incríveis, como Andrew Ng, Robert Crowe e Laurence Moroney.
“TFX é uma plataforma do Google-production-scale machine learning (ML) baseada no TensorFlow. Ele fornece uma estrutura de configuração e bibliotecas compartilhadas para integrar componentes comuns necessários para definir, iniciar e monitorar seu sistema de aprendizado de máquina.” de acordo com o TFX User Guide⁴.
Mas por que você optou por fazer o deploy do seu primeiro modelo de machine learning com um framework não tão simples de primeira?
Existem 3 conceitos que fazem parte do MLOps que são muito importantes quando tratamos de modelos em produção.
- Data Provenance
De onde seus dados vem, como eles surgiram e quais metodologias e processos foram submetidos.
- Data Lineage
Refere-se a sequencia de passos até chegar no final da pipeline.
- Meta-data
São dados que descrevem dados. Servem para explicar as caracteristicas do item que estamos observando. Por exemplo, se estamos verificando uma foto, os metadados podem ser o horário em que a foto foi tirada, quais as configurações da câmera, qual pessoa tirou a foto etc.
Essas 3 peças são chave em modelos de produção, pois ajudam a rastrear as mudanças que ocorrem na vida útil do seu modelo. Suponha que tenhamos um time para coletar e limpar os dados, outro para gerenciar a ingestão, outro para criar/testar o modelo e outro para fazer o deploy. Existem diversas pessoas trabalhando, em diversos arquivos, em diversos ambientes, e isso pode tornar o processo de rastreio de mudanças muito complexo caso não seja feito de forma eficiente.
Imagine que colocamos o modelo em produção, porém, depois de algumas versões, descobrimos que houve um erro na limpeza dos dados. Como rastreamos a versão dos dados, quais transformações foram realizadas, quais os atributos do modelo? Como reproduzimos o mesmo ambiente ao qual os dados foram submetidos anteriormente?
Por isso é importante trabalhar com frameworks que possuem algum tipo de suporte a esses processos. TFX foi desenvolvido para construir e gerenciar fluxos de trabalho em um ambiente de produção. Dessa maneira, os três principais componentes do TFX são:
- Pipelines
- Componentes
- Bibliotecas
2.1 Pipelines
Uma Pipeline TFX é uma sequência de componentes que implementa um pipeline de ML que é projetado especificamente para tarefas de aprendizado de máquina escalonáveis e de alto desempenho. Isso inclui a modelagem, o treinamento, a exibição de inferências e o gerenciamento de implantação em destinos on-line, mobile e JavaScript. Os componentes são construídos usando bibliotecas TFX que também podem ser usadas individualmente. A Pipeline possui suporte para diversos orquestradores, como Apache Airflow, Apache Beam e Kubeflow Pipelines.
2.2 Componentes
Um conjunto de componentes padrão que você pode usar como parte de um pipeline ou de seu script de treinamento de ML. Os componentes padrão TFX fornecem funcionalidade comprovada para ajudá-lo a começar a construir um processo de ML com facilidade.
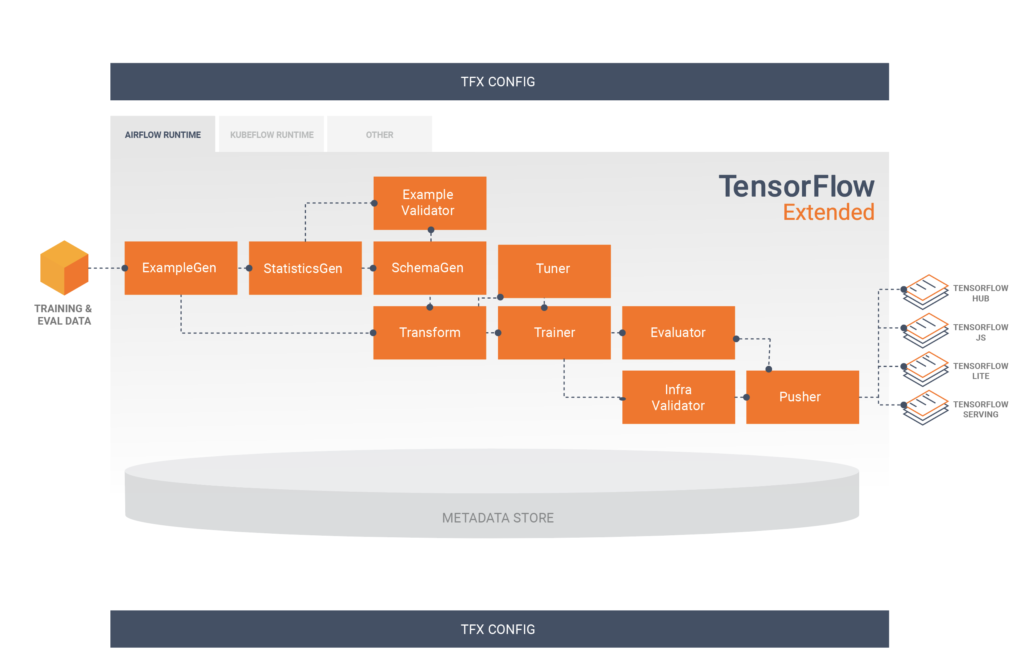
Para entender como nossa pipeline foi montada, precisamos primeiro entender os componentes dela. TFX possui diversos tutoriais explicando como usar os componentes. Normalmente, uma pipeline do TFX inclui os seguintes componentes:
- ExampleGen é o componente de entrada inicial de um pipeline que processa e, opcionalmente, divide o conjunto de dados de entrada. Consome arquivos de fontes externas, como CSV, TFRecord, Avro, Parquet e BigQuery.
- StatisticsGen calcula as estatísticas do conjunto de dados.
- SchemaGen examina as estatísticas e cria um esquema de dados.
- ExampleValidator procura anomalias e valores ausentes no treinamento e fornecimento dos dados, como detecção de desvios de dados.
- Transform realiza a engenharia de atributos no conjunto de dados. Nesse componente realizamos todas as transformações/criações de variáveis do nosso modelo. Um ponto importante desse componente é que ele gera um grafo que guarda as propriedades globais dos dados, que será utilizado tanto no treinamento quanto na inferência, oferecendo confiabilidade.
- Trainer treina o modelo. É nesse componente que especificamos onde e como ele irá ser treinado, além de definir toda a arquitetura do mesmo.
- Tuner ajusta os hiperparâmetros do modelo. O tuner pode ser executado em todas as execuções da pipeline, ou também pode ser importado, caso deseje realizar o ajuste de hiperparâmetros somente de tempos em tempos.
- Evaluator realiza uma análise profunda dos resultados do treinamento e ajuda a validar os modelos exportados, garantindo que eles sejam bons o suficiente para serem enviados para produção. Nesse componente é possível especificar thresholds de validação de métricas, evitando que o modelo vá para produção se não atingir os limites.
- InfraValidator verifica se o modelo pode ser exibido da infraestrutura e impede que o modelo inválido seja enviado.
- Pusher implanta o modelo em uma infraestrutura de exibição. É aqui onde especificamos onde o modelo irá ser servido.
- BulkInferrer executa o processamento em lote em um modelo com solicitações de inferência sem rótulo.
2.3 Bibliotecas
Bibliotecas que fornecem a funcionalidade básica para muitos dos componentes padrão. Você pode usar as bibliotecas TFX para adicionar essa funcionalidade aos seus próprios componentes personalizados ou usá-los separadamente.
Basicamente, uma Pipeline TFX é composta de componentes, que são compostos de bibliotecas.
3. Acompanhamento e Gerenciamento de Experimentos
Um passo que considero muito importante na construção do modelo é o de acompanhamento e gerenciamento de experimentos. Na construção do modelo, você irá rodar diversos experimentos, que podem incluir:
- diferentes modelos com diferentes hiperparâmetros
- diferentes dados de treinamento e teste
- diferentes features
- pequenas alterações no código
E esses diversos experimentos irão produzir métricas diferentes. Manter registros de todas essas informações não é uma tarefa simples, mas muito importante, principalmente para acompanhar o progresso do modelo, comparando diferentes experimentos para termos confiança no resultado final.
E é ai que entra o acompanhamento e gerenciamento de experimentos. É um processo onde salvamos todas as informações que são importantes para cada experimento que rodamos. Cada projeto tem seu próprio set de informações que são importantes salvar, que podem incluir:
- código utilizado para cada arquivo
- configurações de ambiente
- versões dos datasets
- configurações de hiperparâmetros
- métricas de desempenho
- tipo de modelo utilizado
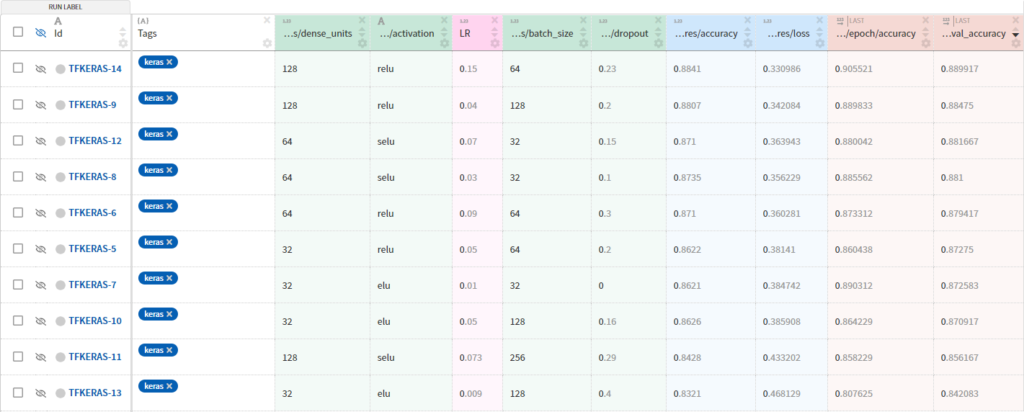
Existem diversas maneiras de salvar essas informações, mas para projetos grandes, é muito importante que você tenha um controle sobre o que está sendo feito. Para isso, existem diversas ferramentas disponíveis, como CometML, Weights and Biases (WandB), MLFlow.
No nosso projeto optamos por utilizar o Neptune.
“O Neptune é um repositório de metadados para qualquer fluxo de trabalho MLOps. Ele foi construído para equipes de pesquisa e produção que realizam muitos experimentos. Ele permite monitorar, visualizar e comparar milhares de modelos de ML em um só lugar.” de acordo com J. Patrycja⁸.
O Neptune oferece suporte ao rastreamento de experimentos, registro de modelo e monitoramento de modelo, e é projetado de uma forma que permite fácil colaboração. Ele também possui integração com o TensorFlow, tornando muito simples de monitorarmos todos os experimentos em um só lugar.
4. Depoy do modelo com Vertex AI e TFX Pipelines
Quando estamos fazendo o deploy de um modelo, precisamos pensar em como vamos entregá-lo para nosso usuário final. No nosso caso, precisamos disponibilizar o modelo através de uma API para que possamos enviar os dados de previsão e receber as respostas.
Para construir nossa pipeline, optamos em trabalhar interamente com o Google Cloud. Como orquestrador, utilizamos o Kubeflow Pipelines, visto que a maioria dos tutoriais são feitos através dele. Existem diversos tutoriais ensinando como integrar sua TFX Pipeline no Cloud, como em [1], [2] e [3].
Decidimos construir nossa pipeline utilizando a Vertex AI, a nova plataforma plataforma de AI da Google. Optamos pela Vertex AI por dois motivos:
- Ela é mais barata (no nosso caso) comparada com a AI Platform Pipelines. As pipelines do Vertex não necessitam de clusters ativos o tempo inteiro, apenas são cobrados custos por execução de cada run e custos associados à utilização de recursos computacionais para treinamento/previsão do mdoelo.
- Diferentemente do GKE, não precisamos gerenciar a infraestrutura/servidores/saúde dos nossos componentes, pois ela é uma plataforma autogerenciada.
De acordo com a documentação, a Vertex AI Pipelines pode executar pipelines criados usando o SDK do Kubeflow Pipelines v1.8.9 ou posterior ou o TensorFlow Extended v0.30.0 ou posterior.
Embora nossa Pipeline seja executada no Vertex AI, optamos por treinar e servir nosso modelo na AI Platform. A Vertex AI é uma plataforma recente, com limitações que serão aprimoradas com o tempo, dessa maneira, até a data de escrita desse artigo, existem funcionalidades importantes que ainda não existem para modelos servidos, como especificar a assinatura de um SavedModel TensorFlow na hora de fazer o predict request.
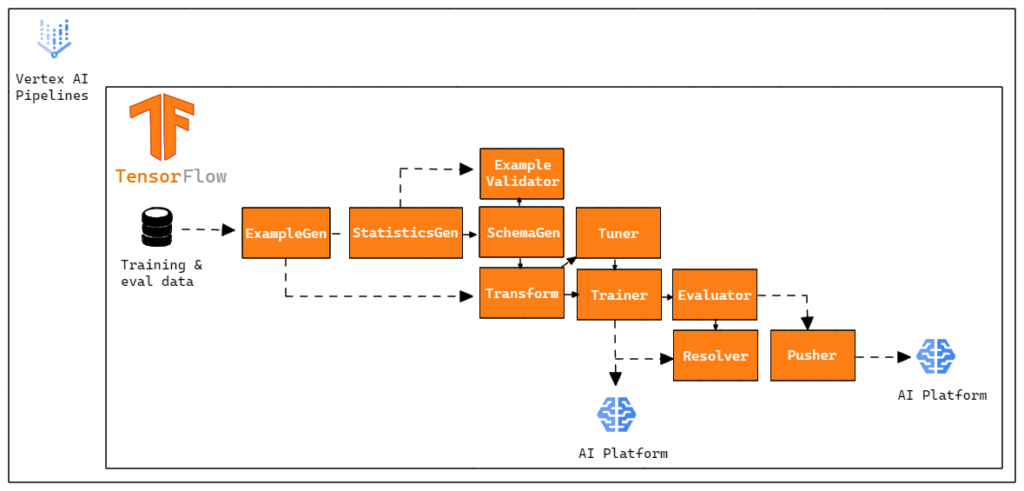
Cada componente é responsável por uma tarefa dentro da TFX Pipeline e, muitas vezes, um componente depende dos outputs do outro. No nosso caso, optamos por não utilizar os componentes InfraValidator e BulkInferrer. Porém, optamos por adicionar um nó a mais na nossa pipeline, o Resolver. Resolver é um nó especial do TFX que lida com resolução de artefatos especiais, no nosso caso foi utilizado para especificar o último modelo base dentro do componente Evaluator.
Então, nossa Vertex Pipeline é composta dessa maneira:
5. Monitoramento
Depois de executada a pipeline, nosso modelo estará disponível para previsões. Porém, isso não significa que nosso trabalho acabou, mas sim que apenas começou. Ao implantarmos um modelo que tem viés comercial, é essencial verificar o desempenho do modelo regularmente. Como os modelos não operam em um ambiente estático, o desempenho do modelo de ML pode degradar-se ao longo do tempo. A distribuição dos dados pode mudar, ocasionando em desvios e consequentemente o modelo terá seu desempenho reduzido. Para manter o desempenho do modelo em produção, é necessário registrar os dados de serviço e compará-los com os dados de treinamento, verificando se a capacidade preditiva do modelo sofreu alguma alteração.
Por isso, precisamos monitorar o modelo. Optamos por registrar as solicitações de serviço do nosso modelo, esse processo registra uma amostra das solicitações e respostas de previsão on-line em uma tabela do BigQuery.
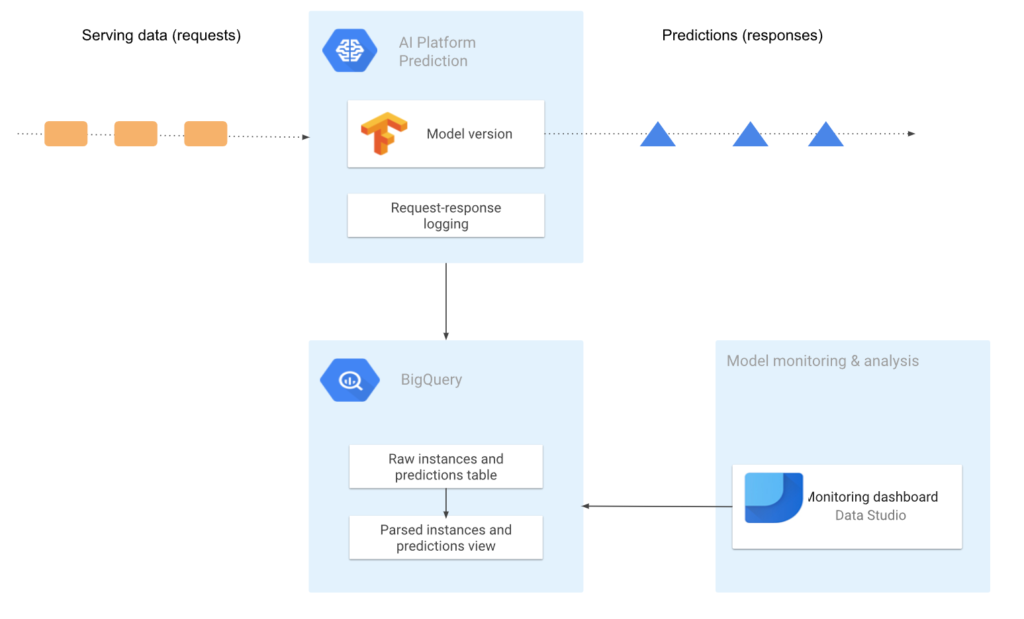
Com esses registros, podemos analisar os dados, calcular estatísticas, visualizar o desvio e o deslocamento dos dados. Esse processo é indispensável para se ter um modelo que evolui de maneira saudável, dados de serviço podem alterar sua distribuição e isso acarretará em uma queda de desempenho no nosso modelo, indicando que é necessário retreinar/reajustar o modelo. Como os dados serão registrados em uma tabela do BigQuery, é muito fácil para gerarmos visualizações e relatórios sobre a distribuição dos dados e as previsões do modelo, um exemplo de ferramenta a ser utilizada é o Data Studio.
6. CI/CD
Agora, vamos para o passo final do nosso projeto. Imagine que temos dezenas de modelos, com centenas de arquivos em produção, e regularmente precisamos fazer ajustes, como ajustar o dataset, criar variáveis, retreinar o modelo, ajustar hiperparâmetros etc. Como podemos automatizar esse processo para que qualquer alteração no projeto seja detectada, testada e o novo modelo seja automaticamente implementado?
“Em engenharia de software, Integração Contínua (CI) e Entrega Contínua (CD) são dois conceitos muito importantes. CI é quando você integra mudanças (novos recursos, confirmações de código aprovado, etc.) em seu sistema de forma confiável e contínua. O CD é quando você implanta essas mudanças de maneira confiável e contínua. CI e CD podem ser executados isoladamente e também em conjunto.” de acordo com P. Chansung; P. Sayak⁶
Pipelines CI/CD permitem que o nosso software lide com mudanças no código, testes, entregas, entre outros. Podemos automatizar o processo de implementação de mudanças, testes e entregas, de maneira que qualquer alteração no projeto seja detectada, testada e o novo modelo seja implementado automaticamente. Isso permite que nosso sistema seja escalável e adaptável a mudanças, além disso fornecer rapidez e confiabilidade, reduzindo erros por falhas repetitivas. Caso queira entender mais sobre a importância do CI/CD e o porquê dele ser necessário para seu projeto, confira esse artigo.
Nesse projeto, criamos a seguinte CI/CD pipeline:
1. Criamos um repositório no Github, contendo todo o código da nossa TFX Pipeline que será executada no Vertex AI.
2. Configuramos um fluxo no GitHub Actions, que irá disparar a cada push no main branch, e checará se houveram mudanças em diretórios específicos do nosso repositório.
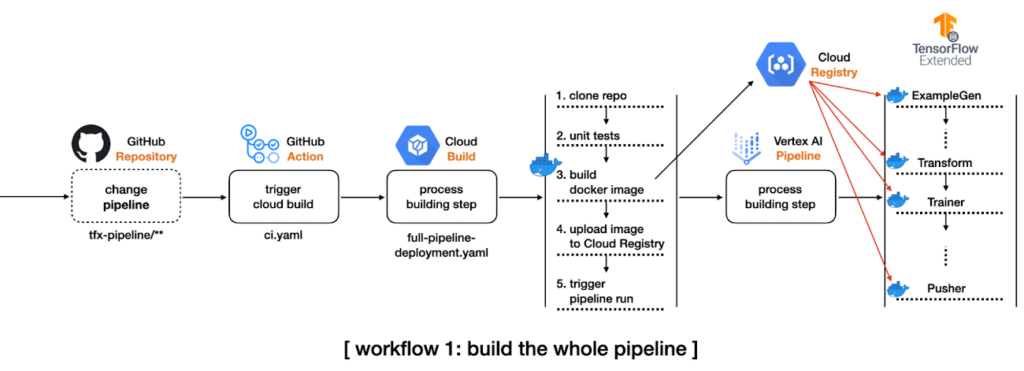
3. Caso hajam mudanças no diretório que contenham arquivos relativos à configurações da pipeline, o fluxo irá iniciar um Cloud Build Process, que irá clonar o repositório inteiro, construir uma nova imagem Docker baseada nas mudanças do código, subir a nova imagem para um Google Container Registry e submeter a TFX Pipeline no Vertex AI.
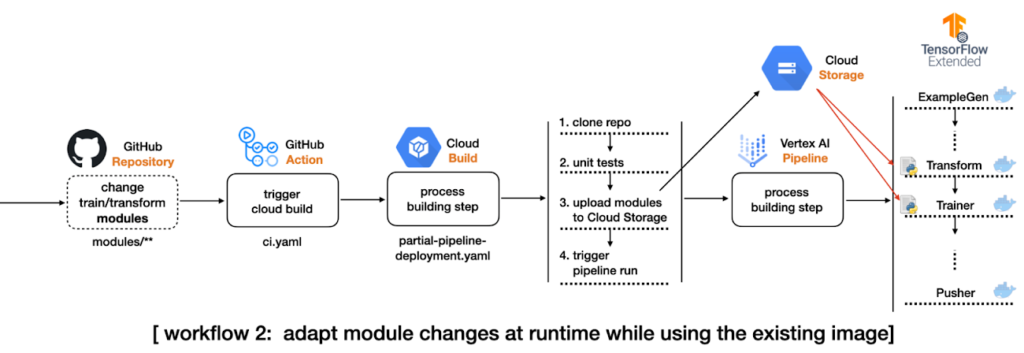
4. Caso hajam mudanças no diretório que contenham mudanças no código do modelo, do pré-processamento ou dos dados de treinamento, o fluxo irá iniciar um Cloud Build Process, que irá clonar o repositório inteiro, copiar apenas os módulos alterados para os diretórios dos módulos no GCS Bucket e submeter a TFX Pipeline no Vertex AI, sem a necessidade de construir uma nova imagem Docker.
Após configurada a pipeline, qualquer push feito no repositório irá ativar o GitHub Actions, que irá verificar se houveram mudanças e automaticamente executar a pipeline, fazendo o deploy do nosso modelo de machine learning automaticamente. É importante ressaltar que a TFX Pipeline irá seguir o fluxo normalmente, ou seja, caso o modelo candidato não seja aprovado no Evaluator, por exemplo, o modelo não será implementado.
Existem outras diversas melhorias possíveis para a CI/CD Pipeline, como:
- Validação de dados de treinamento
- Teste de unidade dos diferentes módulos, como tipos de dados aceitáveis, quantidade de dados esperados etc.
- Testar se os outputs do modelo não produz valores nulos
- Testar o serviço de previsão, chamando a API de serviço com dados de teste para verificar se o modelo está funcionando corretamente
- Implantação automática de um ambiente de pré-produção, por exemplo, uma implantação acionada pela mesclagem de código para a ramificação principal após os revisores aprovarem as alterações
7. Conclusão
Fazer o deploy de um modelo de machine learning para usuários não é uma tarefa fácil, construir o modelo é apenas o primeiro passo. Para fazer o deploy do nosso primeiro modelo de machine learning e manter o desempenho do nosso modelo, precisamos monitorar suas previsões e oferecer alternativas que tornem nosso processo escalável e adapatável a mudanças. Além disso, é importante que guardemos dados referentes à execução das pipelines, para que nossos processos sejam reproduzíveis e que o processo de correção de erros seja eficiente. Utilizar ferramentas que auxiliem o processo é essencial para abstrair a complexidade do projeto, tornando-o mais escalável e mais fácil de manter.
Caso queira enviar alguma sugestão, tenha alguma dúvida ou queira apenas trocar um papo, podem falar comigo através do meu perfil no Linkedin, também compartilho conteúdos regularmente aqui no Medium. Espero que tenha sido útil, se gostou do conteúdo, curte e compartilha pra espalhar esse conhecimento :).
8. Referências
[1] TFX on Cloud AI Platform Pipelines (05 Novembro 2021), TensorFlow.
[2] O. Rising, Deep Dive into ML Models in Production Using TensorFlow Extended (TFX) and Kubeflow (12 Novembro 2021), Neptune Blog.
[3] Simple TFX Pipeline for Vertex Pipelines (08 Dezembro 2021), TensorFlow.
[4] The TFX User Guide (14 Dezembro 2021), TensorFlow.
[5] MLOps: Continuous delivery and automation pipelines in machine learning (07 Janeiro 2020), Google.
[6] P. Chansung; P. Sayak, Model training as a CI/CD system: Part I (6 Outubro 2021), Google.
[7] ML model monitoring: Logging serving requests by using AI Platform Prediction (12 Março 2021), Google.
[8] J. Patrycja, 15 Best Tools for ML Experiment Tracking and Management (25 Outubro 2021), Neptune Blog.