
Understand what recommender systems are and how they work, what types there are and how they can help guide our decisions
1. Introduction
You’ve probably noticed that when you go to a particular product or search on a topic, you’ll start getting referrals for similar products, or your feed will start showing posts similar to the ones you clicked on. That’s when you wonder: am I being watched?

2. What is a Recommender System?
A recommender system is a set of algorithms that combine techniques to suggest items similar to what the user has shown interest. These techniques can come from many fields, be they machine learning, information retrieval etc.
The main purpose of a recommender system is to suggest relevant items to the user. They can save time, improve user experience and increase a company’s profit. Imagine that you are on a website that has thousands of products, clearly you would not have time to go through each product to find what you are looking for. To improve your experience and help you find your product, the recommender system will suggest products that match your preferences.
Recommender systems are currently widely used in several areas, such as e-commerce, news sites, streaming etc., all of them are built with the aim of personalizing the user experience, transforming it into a more pleasant environment.
3. Types of Recommender Systems
There are basically three types of recommendation systems:
- Content-Based Filtering
- Collaborative Filtering
- Hybrid
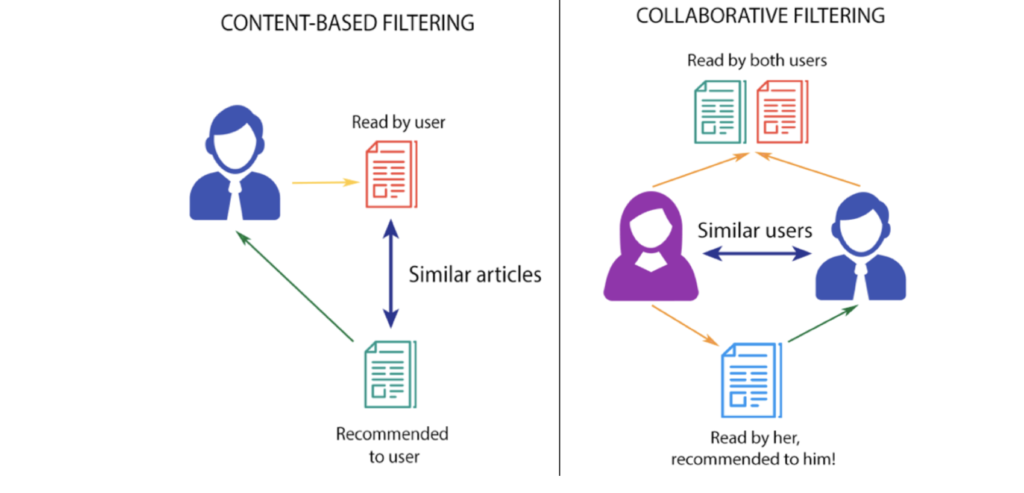
Each system has its own peculiarities, so let’s discuss a little more about each type.
3.1 Content-Based Filtering
It is the one in which the attributes or characteristics of the items are taken into account to carry out the recommendation. For example, if we’re looking to recommend songs, we’ll look at the genre, duration, singer, and various other attributes that make up the item.
Pros
- The amount of data required for the system to perform is much less.
- It is only necessary to know the user himself, that is, it is not necessary to identify users with similar preferences.
- It does not suffer from the cold start problem, a known issue in recommender systems that addresses the algorithm’s inability to recommend items or users for which it does not have enough information.
Cons
- Content-based algorithms suffer from a lack of diversity, that is, they can only recommend items that are strictly similar.
- They strictly depend on the data filled in correctly and on the correct feeding of the systems.
- It is not possible to explore the quality of the items, that is, as much as these items are very different in terms of quality, if they have the same characteristics, they will be treated as equal.
3.2 Collaborative Filtering
These are systems that analyze the preferences of other users to make recommendations, and are basically divided into two types:
3.2.1 Memory Based
In this class, similarity matrices between all users or items, depending on the approach, are computed and the matrix representation is kept in memory. By identifying this similarity, it is possible to recommend new items.
Okay, we created the matrix, but now what? how do we compute similarity between users or items?
There are several ways of computing similarity between vectors, such as euclidean, minkowski, jaccard etc., but the one we’ll talk a little more about is cosine similarity, which is a measure of similarity between two vectors where the cosine of the angle between the vectors is calculated. This metric is widely used because even though the magnitude of the vectors is different, they can still be similar.
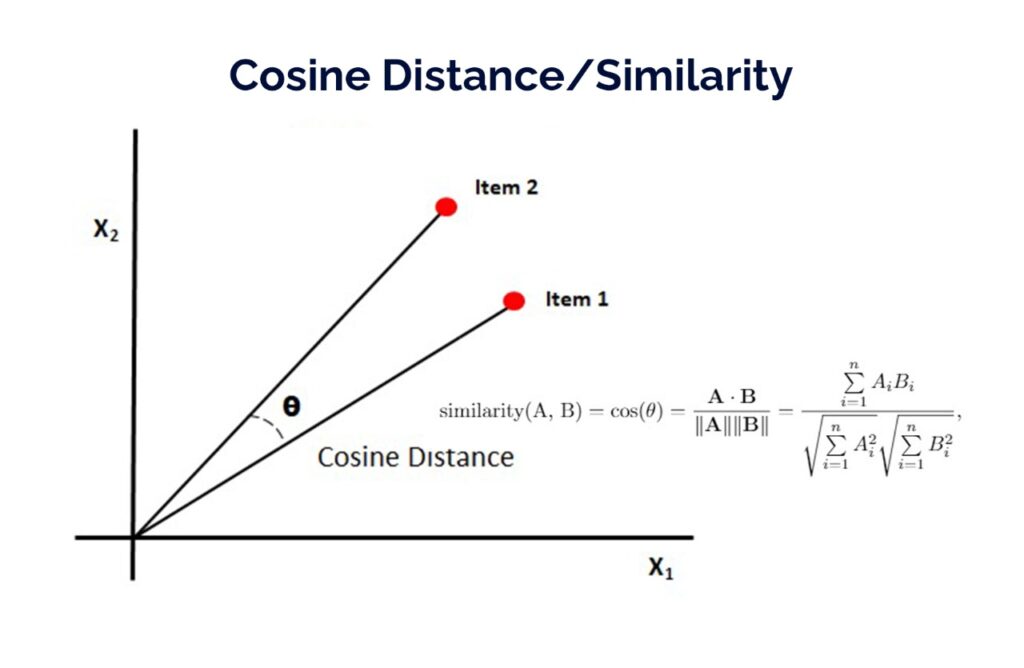
The cosine value varies between 0 and 1. Thus, the most similar a vector can be to the other is when the angle between them is 0º, where the cosine has a value of 1. So the greater the cosine similarity, the greater the similarity between vectors.
Thus, within memory-based algorithms, we can use two approaches, based on users or items.
3.2.1.1 User-User
“Consider as similars users who give similar ratings to a common set of items.” — Everton Lima Aleixo
This is the most common type of approach, where a similarity matrix is computed across all users. The biggest problem about this approach is that building this matrix consumes a lot of resources, since the number of users is huge and the number of ratings is not, resulting in a sparse matrix.
First, the matrix is assembled considering that each user is a vector of size n. And then compute the similarity between all users.
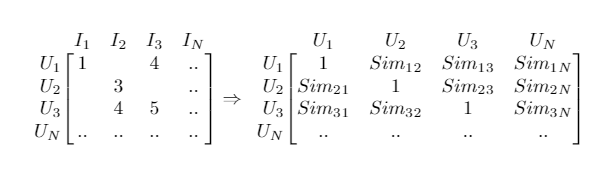
3.2.1.2 Item-Item
“Consider as similars items that have undergone similar ratings by the same group of users.” — Everton Lima Aleixo
One of the great advantages of this approach, in addition to being computationally less demanding since there are generally far fewer items than users, is that an item’s ratings don’t change as quickly as a user’s ratings.
First, the matrix is assembled considering that each item is a vector of size n. And then compute the similarity between all items.
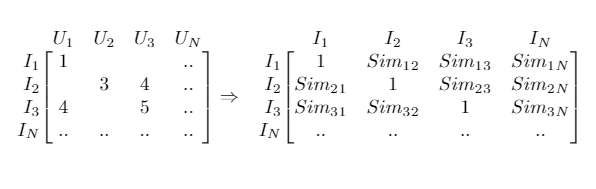
3.3 Hybrid
Intuitively, the hybrid system combines the two techniques, using item characteristics and user preferences to generate recommendations.
4. Types of approach
In any type of recommender system, an essential piece of data for effectiveness is the user’s history. To identify user preferences, we can classify the approach into two types: explicit and implicit.
The explicit approach is one in which the user firmly demonstrates his opinion about a certain item, such as rating or liking a product.
The implicit approach, on the other hand, is one in which the user leaves his intention indirectly, such as the time spent on a page, the number of views in a given publication etc.
One problem with explicit data is that this behavior demands extra work for the user, and not everyone is bothered to leave their opinion about the item, resulting in very sparse data. Also, when it comes to ratings, people may have different standards, a 4 star rating given by a person may not be the same rating for you, although there are some ways around this issue, it’s still something to take into consideration.
As for implicit data, the amount of data is not an issue, as there are many more interactions. The biggest problem with implicit data is that they are not an exact indicator of interest, imagine the following situation: you are browsing the internet and accidentally clicked on a publication that does not interest you, from now on you will start receiving recommendations about a subject that is not of interest to you. Also, they are more susceptible to bots and manipulation.
So, in general, the explicit approach brings more valuable data to the analysis since the user has clearly demonstrated his intention, but it is rarer data to be acquired.
5. Metrics
Evaluating a recommender system is not an easy task. Part of the work is subjective, we’re trying to recommend something to someone we don’t know based on their online behavior, that’s complicated. There are several metrics to assess the functioning of your system, especially if you are evaluating it offline, that is, without public interaction. Let’s briefly list and discuss some offline metrics and how they work.
- Mean Absolute Error (MAE)
MAE is a well-known and used metric to measure accuracy.
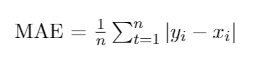
Calculate the absolute difference between the predicted value and the actual value, repeat this for each element, add up all the values and divide by the number of items.
Since it is an accuracy error, the smaller this metric, the better.
- Root Mean Squared Error (RMSE)
Another well-known metric similar to MAE is RMSE.
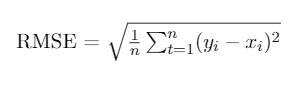
It is calculated using the square root of the square of errors, so it is more sensitive to outliers than MAE.
As it is also a metric that measures error, the smaller the better.
- Hit Rate
Hit Rate is a well-known and used metric for recommendation systems. In this case, let’s understand the logic behind this metric step-by-step:
- List all items in a user’s history, that is, all items that this user has interacted with.
- Intentionally remove one of these items. This technique is called Leave-One-Out Cross Validation.
- Use all other items to train the recommender system and generate a list of Top N Recommendations.
- If the removed item appears in the Top N Recommendations list, consider it a hit. If not, it’s not a hit.
- Repeat this for all users, add up the hits and divide by the number of users. This way we will have the Hit Rate of the system.
Basically we’re measuring our system’s ability to recommend this item that’s been removed, and the higher that ability, the better. A known issue with this metric is that we need a lot of data for it to perform properly.
In addition, it has several variations, such as the Average Reciprocal Hit Rate (ARHR), the Cumulative Hit Rate (cHR) and the Rating Hit Rate (rHR).
- Coverage
Accuracy is not the only thing we must consider. Coverage represents the percentage of items or users that the system is able to recommend.
Ideally the larger this metric the better. However, it is affected if we do not have enough ratings for the items, resulting in the system not being able to predict for these.
- Diversity
Diversity is a metric aimed at the system’s ability to recommend items outside the user’s similarity profile. This similarity is usually measured between items or users, depending on the approach, and is calculated using the item attributes or ratings.
It is important to have diversity to introduce the user to other experiences, but care must be taken so that the system does not become a random item recommender.
- Novelty
Finally, novelty is the system’s ability to recommend items that are not as well known or popular.
One of the ways to calculate is to create a popularity ranking for all items, create the matrix of top N recommendations, enter each user in this matrix and in each item of that user and add the ranking position that this item occupies in the ranking of popularity. Then, just divide the sum of the rankings by the total number of ratings in the matrix of top N recommendations.
Similar to diversity, a high novelty value is not always a good indicator, as we may simply be recommending random items or that users don’t like.
CAUTION!
As we are testing our system offline, all of these metrics try to measure how our system behaves in relation to the predictions it is making, and this can cause false confidence. Our system can perform wonderfully well in evaluations, but when it goes out into the real world, the final user just doesn’t like them.
So, if you want to be sure of your system’s effectiveness, the best way to do this is through the famous A/B tests.
- A/B Test
The A/B Test is one of the best known and most efficient methods to validate an experiment. It consists of isolating two variables, A and B, and measuring the approval of each variable in a controlled environment. By testing changes to the system through controlled online experiments, we will have a greater understanding if users are interacting more and if our system is performing well.
6. Conclusion
Recommender systems are already part of our life and often we don’t even realize it. Good recommendation systems are meant to guide our decisions, helping us to filter through the huge amount of information online. Both the chosen techniques and data quality are important aspects for the quality of the system, and to measure the quality of these systems we can use metrics to measure both the behavior of the system and the engagement of users.
7. References
[1] S. Rafael Glauber Nascimento, Sistema de Recomendação baseado em conteúdo textual: avaliação e comparação (2014), Universidade Federal da Bahia.
[2] A. Taufik, Recommendation System for Retail Customer (2020), Medium.
[3] B. Anna, Recommender Systems — It’s Not All About the Accuracy (2016), Lab41.
[4] P. Giorgos, Popular evaluation metrics in recommender systems explained (2019), Medium.
[5] G. Rafael; L. Angelo, Collaborative Filtering vs. Content-Based Filtering: differences and similarities (2019), Universidade de Feira de Santana.
[6] A. Everton Lima, Item-based-adp: análise e melhoramento do algoritmo de filtragem colaborativa item-based. 96 f. Dissertação (Mestrado em Ciência da Computação) (2014), Universidade Federal de Goiás.