
Entendendo Sistemas de Recomendação
Entenda o que são e como funcionam sistemas de recomendação, quais tipos existem e como eles podem ajudar a guiar nossas decisões
1. Introdução
Com certeza você já deve ter percebido que ao acessar um determinado produto ou ao pesquisar algum assunto, você começará a receber indicações de produtos semelhantes, ou seu feed começará a exibir publicações semelhantes às que você clicou. É nessa hora que você imagina: será que estou sendo espionado?

2. O que é um sistema de recomendação?
Um sistema de recomendação é um conjunto de algoritmos que combina técnicas para sugerir itens semelhantes ao que o usuário demonstrou interesse. Essas técnicas podem surgir de vários campos, sejam eles do aprendizado de máquinas, da recuperação de informações etc.
O principal objetivo de um sistema de recomendação é sugerir itens relevantes para o usuário. Eles podem economizar tempo, melhorar a experiência do usuário e aumentar o lucro de uma empresa. Imagine que você está em um site que possui milhares de produtos, claramente não teria tempo de passar por cada produto para encontrar o que está procurando. Para melhorar a sua experiência e ajudá-lo a encontrar o seu produto, o sistema de recomendação irá sugerir produtos que correspondam às suas preferências.
Sistemas de recomendação são amplamente utilizados atualmente em diversas áreas, como no e-commerce, sites de notícias, streaming etc., todos eles são construídos com o intuito de personalizar a experiência do usuário, transformando-a em um ambiente mais agradável.
3. Tipos de sistemas de recomendação
Existem, basicamente, três tipos de sistemas recomendação:
- Baseado em Filtragem de Conteúdo
- Filtragem Colaborativa
- Híbrido
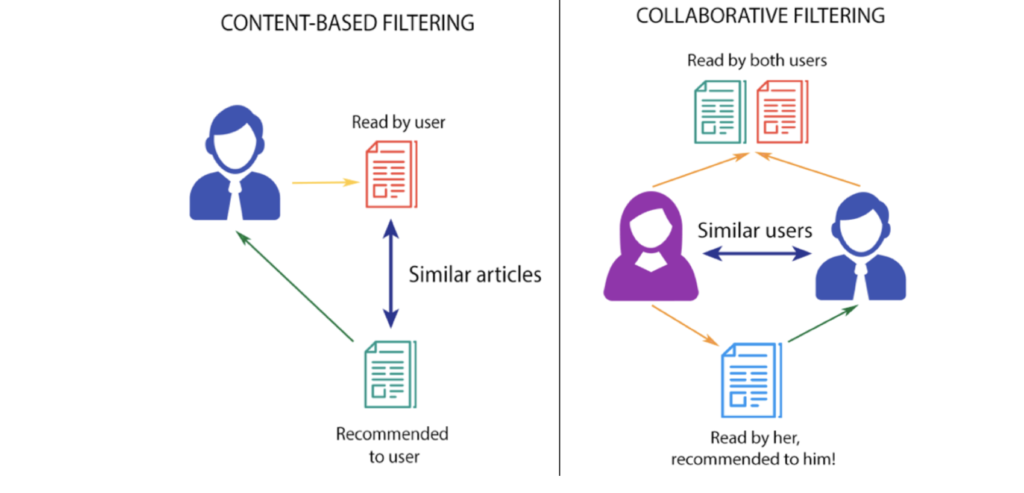
Cada sistema possui suas particularidades, por isso vamos discutir um pouco mais sobre cada tipo.
3.1 Recomendação baseada em conteúdo
É aquela em que os atributos ou características dos itens são levadas em consideração para se realizar a recomendação. Por exemplo, se estivermos querendo recomendar músicas, iremos analisar o gênero, a duração, o cantor e vários outros atributos que compõem o item.
Prós
- A quantidade de dados exigida para o sistema performar é muito menor.
- É necessário conhecer apenas o próprio usuário, ou seja, não é necessário identificar usuários com preferências semelhantes.
- Não sofre com o cold start problem, um problema conhecido em sistemas de recomendação que aborda a incapacidade do algoritmo de recomendar itens ou usuários aos quais ele não possui informações suficiente.
Contras
- Os algoritmos baseados em conteúdo sofrem com a falta de diversidade, ou seja, só conseguem recomendar itens que são estritamente similares.
- Dependem estritamente dos dados preenchidos corretamente e da alimentação correta dos sistemas.
- Não é possível explorar a qualidade dos itens, ou seja, por mais que esses itens sejam bem diferentes em termos de qualidade, se possuírem as mesmas características, serão tratados como iguais.
3.2 Sistemas de recomendação baseados em filtragem colaborativa
São sistemas que analisam as preferências dos outros usuários para realizar as recomendações, e são basicamente divididos em dois tipos:
3.2.1 Baseados em memória
Nessa classe, são computadas matrizes de similaridade entre todos os usuários ou itens , dependendo da abordagem, e a representação da matriz é mantida em memoria. Ao identificar essa similaridade, é possível recomendar novos itens.
Certo, criamos a matriz, mas e agora? como computamos a similaridade entre os usuários ou itens?
Existem diversos tipos de se computar a similaridade entre vetores, como a distância euclidiana, de minkowski, jaccard etc., mas a que vamos falar um pouco mais sobre é a similaridade por cosseno (cosine similarity), que é uma medida de similaridade entre dois vetores onde o cosseno do ângulo entre os vetores é calculado. Essa métrica é bastante utilizada porque mesmo que a magnitude dos vetores seja diferente, eles ainda podem ser similares.
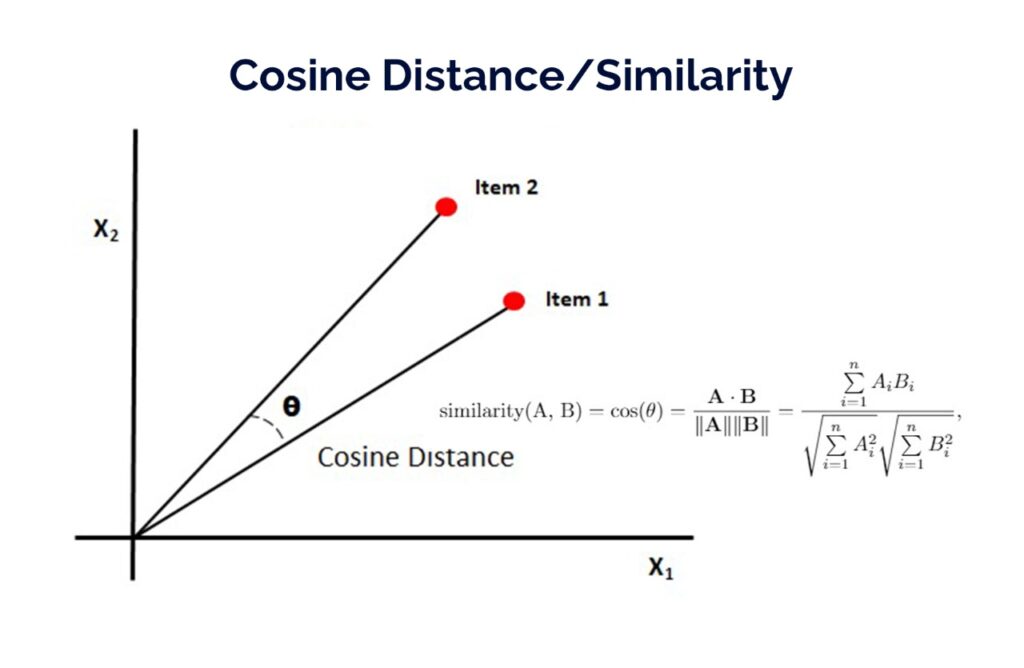
O valor do cosseno varia entre 0 e 1. Dessa maneira, o mais similar que um vetor pode ser do outro é quando o ângulo entre eles é de 0º, onde o cosseno tem valor 1. Então quanto maior a similaridade por cosseno, maior a similaridade entre vetores.
Dessa maneira, dentro dos algoritmos baseados em memória, podemos utilizar duas abordagens, baseadas em usuários ou em itens.
3.2.1.1 User-User
“Considera como similares usuários que deram avaliações semelhantes a um conjunto comum de itens.” — Everton Lima Aleixo
Esse é o tipo mais comum de abordagem, onde é computada uma matriz de similaridade entre todos os usuários. O grande problema dessa abordagem é que montar essa matriz consome muitos recursos, visto que o número de usuários é enorme e a quantidade de avaliações não, resultando em uma matriz esparsa.
Primeiro, monta-se a matriz considerando que cada usuário é um vetor de tamanho n. E depois, computa-se a similaridade entre todos os usuários.
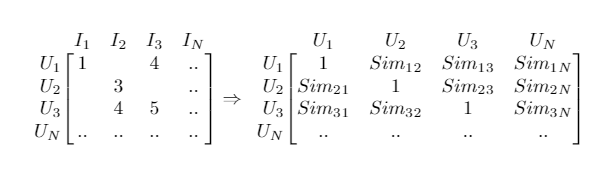
3.2.1.2 Item-Item
“Considera como similares itens que sofreram avaliações semelhantes por um mesmo grupo de usuários.” — Everton Lima Aleixo
Uma das grandes vantagens dessa abordagem, além de ser computacionalmente menos exigente visto que geralmente existem muito menos itens que usuários, é a de que as avaliações de um item não mudam tão rapidamente quanto as avaliações de um usuário.
Primeiro, monta-se a matriz considerando que cada item é um vetor de tamanho n. E depois, computa-se a similaridade entre todos os itens.
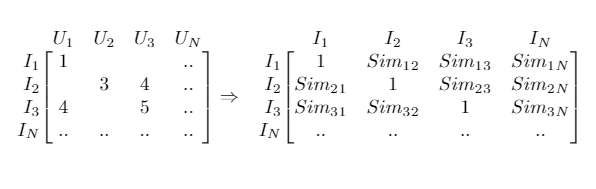
3.2.2 Baseados em modelo
Os algoritmos baseados em modelo utilizam o conjunto de avaliações dos usuários para construir um modelo capaz de realizar predições para então recomendar novos itens. Normalmente esses modelos são construídos através do aprendizado de máquina. Um dos algoritmos mais famosos é o SVD (Singular Value Decomposition).
3.3 Sistema híbrido
Intuitivamente, o sistema híbrido combina as duas técnicas, utilizando as características dos itens e as preferências dos usuários para gerar as recomendações.
4. Tipos de abordagem
Em qualquer tipo de sistema de recomendação, um dado essencial para a efetividade é o histórico do usuário. Para identificar as preferências do usuário, podemos classificar a abordagem em dois tipos: explicita e implícita.
A abordagem explicita é aquela em que o usuário demonstra firmemente sua opinião sobre determinado item, como por exemplo, a nota sobre um produto ou um like.
Já a abordagem implícita é aquela em que o usuário deixa sua intenção de maneira indireta, como por exemplo, o tempo de permanência em uma página, o número de visualizações em determinada publicação etc.
Alguns problemas dos dados explícitos é que esse comportamento gera mais trabalho para o usuário, já que nem todo mundo se incomoda de deixar sua opinião sobre o item, resultando em dados muito esparsos. Além disso, quando tratamos de ratings, as pessoas podem ter padrões diferentes, ou seja, uma avaliação de 4 estrelas dada por uma pessoa pode não ser a mesma avaliação para você, embora existam algumas maneiras de se contornar essa questão, ainda é algo a se levar em consideração.
Já para os dados implícitos, a quantidade de dados não é um problema, visto que existem muito mais interações. O grande problema dos dados implícitos é que eles não são um indicador exato de interesse, imagine a seguinte situação: você está navegando na internet e clicou sem querer em uma publicação que não te interessa, a partir de agora você irá começar a receber recomendações sobre um assunto que não é do seu interesse. Além disso, eles são mais suscetíveis a bots e manipulações.
Então, de maneira geral, a abordagem explicita traz dados mais valiosos para a análise já que o usuário demonstrou claramente sua intenção, porém são dados mais raros de serem adquiridos.
5. Métricas
Avaliar um sistema de recomendação não é uma tarefa fácil. Parte do trabalho é subjetivo, estamos tentando recomendar algo para alguém que não temos conhecemos baseado no comportamento dela online, isso é complicado. Existem diversas métricas para se avaliar o funcionamento do seu sistema, principalmente se você estiver avaliando ele offline, ou seja, sem interação do público. Vamos elencar e discutir brevemente algumas métricas offline e como elas funcionam.
- Mean Absolute Error (MAE)
O MAE é uma métrica muito conhecida e utilizada para se medir acurácia.
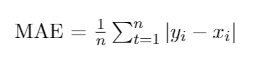
Calcule a diferença absoluta entre o valor previsto e o valor real, repita isso pra cada elemento, some todos os valores e divida pelo número de itens.
Como é um erro de acurácia, quanto menor essa métrica, melhor.
- Root Mean Squared Error (RMSE)
Outra métrica bastante conhecida e similar ao MAE é o RMSE.
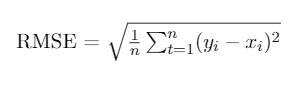
É calculada através da raiz quadrada do quadrado dos erros, por esse motivo ela é mais sensível a outliers do que o MAE.
Como também é uma métrica que mede o erro, quanto menor, melhor.
- Hit Rate
O Hit Rate é uma métrica muito conhecida e utilizada para sistemas de recomendação. Nesse caso, vamos entender a lógica por trás dessa métrica passo a passo:
- Liste todos os itens do histórico de um usuário, ou seja, todos os itens que esse usuário interagiu.
2. Intencionalmente remova um desses itens. Essa técnica é chamada de Leave-One-Out Cross Validation.
3. Utilize todos os outros itens para treinar o sistema de recomendação e gere uma lista de Top N Recomendações.
4. Se esse item que foi removido anteriormente aparecer na lista de Top N Recomendações, considere um hit. Se não, não é um hit.
5. Repita isso para todos os usuários, some os hits e divida pelo número de usuários. Dessa maneira teremos o Hit Rate do sistema.
Basicamente estamos medindo a capacidade do nosso sistema de recomendar esse item que foi removido, e quanto maior essa capacidade, melhor. Um problema conhecido dessa métrica é que precisamos de muitos dados para ela performar adequadamente.
Além disso, ela possui diversas variações, como a Average Reciprocal Hit Rate (ARHR), a Cumulative Hit Rate (cHR) e a Rating Hit Rate (rHR).
- Coverage
Acurácia não é a única coisa que devemos levar em consideração. Coverage representa a porcentagem de itens ou usuários que o sistema sistema é capaz de recomendar.
Idealmente quanto maior essa métrica, melhor. Porém, ela é afetada caso não tenhamos ratings suficientes para os itens, resultando no sistema não ser capaz de prever para estes.
- Diversity
Diversity é uma métrica voltada à capacidade do sistema de recomendar itens fora do perfil de similaridade do usuário. Geralmente essa similaridade é medida entre os itens ou usuários, dependendo da abordagem, e é calculada utilizando os atributos dos itens ou os ratings.
É importante se ter diversidade para introduzir o usuário a outras experiências, mas deve-se ter o cuidado para que o sistema não se transforme em um recomendador de itens aleatórios.
- Novelty
Finalmente, novelty é a capacidade do sistema de recomendar itens que não são tão conhecidos ou populares.
Uma das maneiras de se calcular é criar um ranking de popularidade de todos os itens, criar a matriz de top N recomendações, entrar em cada usuário dessa matriz e em cada item desse usuário e somar a posição do ranking que esse item ocupa no ranking de popularidade. Depois, é só dividir a soma dos rankings pelo número total de ratings da matriz de top N recomendações.
Semelhante à diversity, nem sempre um valor alto de novelty significa um bom indicador, visto que podemos simplesmente estar recomendando itens aleatórios ou que os usuários não gostam.
CUIDADO!
Como estamos testando nosso sistema offline, todas essas métricas procuram medir como nosso sistema se comporta em relação às previsões que ele está fazendo, e isso pode causar uma falsa confiança. Nosso sistema pode performar maravilhosamente bem nas avaliações, mas quando vai para o mundo real, o usuário final simplesmente não gosta delas.
Dessa maneira, se você quiser ter certeza da efetividade do seu sistema, a melhor maneira de fazer isso é através dos famosos testes A/B.
- Teste A/B
O Teste A/B é um dos métodos mais conhecidos e eficientes para se validar um experimento. Consiste em isolar duas variáveis, A e B, e medir a aprovação de cada variável em um ambiente controlado. Testando as mudanças no sistema através de experimentos controlados online, teremos maior compreensão se os usuários estão interagindo mais e se nosso sistema está performando bem.
6. Conclusão
Sistemas de recomendação já fazem parte da nossa vida e muitas vezes nem percebemos. Bons sistemas de recomendação tem o objetivo de guiar nossas decisões, ajudando-nos a filtrar a enorme quantidade de informações online. Tanto as técnicas escolhidas quanto a qualidade dos dados são importantes aspectos para a qualidade do sistema, e para medir a qualidade desses sistemas podemos utilizar tanto métricas para medir o comportamento do sistema quanto o engajamento dos usuários.
7. Referências
[1] S. Rafael Glauber Nascimento, Sistema de Recomendação baseado em conteúdo textual: avaliação e comparação (2014), Universidade Federal da Bahia.
[2] A. Taufik, Recommendation System for Retail Customer (2020), Medium.
[3] B. Anna, Recommender Systems — It’s Not All About the Accuracy (2016), Lab41.
[4] P. Giorgos, Popular evaluation metrics in recommender systems explained (2019), Medium.
[5] G. Rafael; L. Angelo, Collaborative Filtering vs. Content-Based Filtering: differences and similarities (2019), Universidade de Feira de Santana.
[6] A. Everton Lima, Item-based-adp: análise e melhoramento do algoritmo de filtragem colaborativa item-based. 96 f. Dissertação (Mestrado em Ciência da Computação) (2014), Universidade Federal de Goiás.